GitSwarm-EE 2017.2-1 Documentation
GitLab Geo
Note: This feature was introduced in GitSwarm 2017.1-1 EE. We recommend you use with at least GitSwarm 2017.2-1 EE.
GitLab Geo allows you to replicate your GitLab instance to other geographical locations as a read-only fully operational version.
Overview
If you have two or more teams geographically spread out, but your GitLab instance is in a single location, fetching large repositories can take a long time.
Your Geo instance can be used for cloning and fetching projects, in addition to reading any data. This will make working with large repositories over large distances much faster.
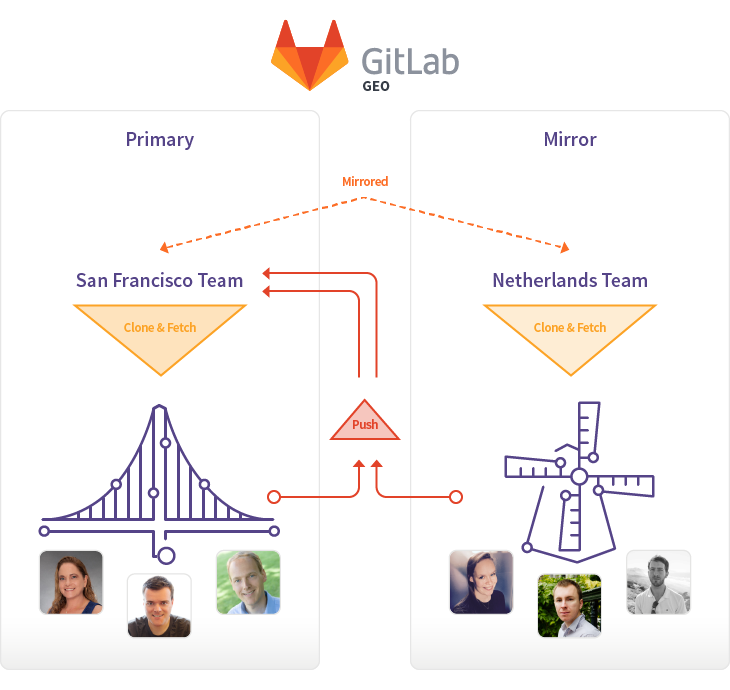
When Geo is enabled, we refer to your original instance as a primary node and the replicated read-only ones as secondaries.
Keep in mind that:
- Secondaries talk to primary to get user data for logins (API), and to clone/pull from repositories (HTTP(S)/SSH).
- Primary talks to secondaries to notify for changes (API).
Setup instructions
In order to set up one or more GitLab Geo instances, follow the steps below in this exact order:
- Follow the steps to install GitLab Enterprise Edition on the server that will serve as the secondary Geo node. Do not login or set up anything else in the secondary node for the moment.
- Setup the database replication (
primary <-> secondary (read-only)topology) - Configure GitLab to set the primary and secondary nodes.
After setup
After you set up the database replication and configure the GitLab Geo nodes, there are a few things to consider:
- When you create a new project in the primary node, the Git repository will appear in the secondary only after the first
git push. You need an extra step to be able to fetch code from the
secondaryand push toprimary:- Clone your repository as you would normally do from the
secondarynode Change the remote push URL following this example:
bash git remote set-url --push origin [email protected]:user/repo.git
- Clone your repository as you would normally do from the
Important: The initialization of a new Geo secondary node on versions older than GitSwarm 2017.2-1 requires data to be copied from the primary, as there is no backfill feature bundled with those versions. See more details in the Configure GitLab step.
Current limitations
- You cannot push code to secondary nodes
- Git LFS is not supported yet
- Git Annex is not supported yet
- Primary node has to be online for OAuth login to happen (existing sessions and git are not affected)
Frequently Asked Questions
Can I use Geo in a disaster recovery situation?
There are limitations to what we replicate (see What data is replicated to a secondary node?). In an extreme data-loss situation you can make a secondary Geo into your primary, but this is not officially supported yet.
If you still want to proceed, see our step-by-step instructions on how to manually promote a secondary node into primary.
What data is replicated to a secondary node?
We currently replicate project repositories and the whole database. This means user accounts, issues, merge requests, groups, project data, etc., will be available for query. We currently don't replicate user generated attachments / avatars or any other file in public/upload. We also don't replicate LFS / Annex or artifacts data (shared/folder).
Can I git push to a secondary node?
No. All writing operations (this includes git push) must be done in your primary node.
How long does it take to have a commit replicated to a secondary node?
All replication operations are asynchronous and are queued to be dispatched in a batched request every 10 seconds. Besides that, it depends on a lot of other factors including the amount of traffic, how big your commit is, the connectivity between your nodes, your hardware, etc.
What happens if the SSH server runs at a different port?
We send the clone url from the primary server to any secondaries, so it doesn't matter. If primary is running on port 2200 clone url will reflect that.