Failover
Failover is the process by which a standby server (or forwarding-standby server) replaces a server that provides standard, commit-server, or edge-server services. The server replaced during a failover is generally referred to as a "master" server.
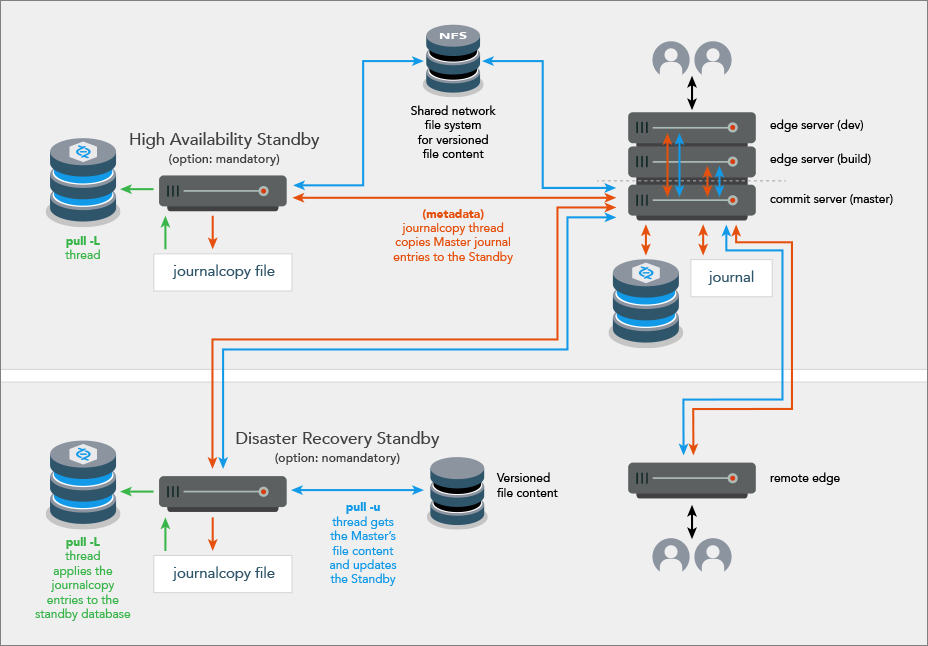
High Availability and Disaster Recovery
The Failover feature supports two scenarios, High Availability (HA) and Disaster Recovery (DR).
High Availability (HA)
-
The master can be configured as a master server, a Commit Server, or an Edge Server.
-
Typically, the standby server is in the same hardware rack as the master server
-
Typical use case: scheduled maintenance, but also possible if the master hardware fails
-
Typically, the master server participates in the failover process:
-
disabling itself in an orderly fashion
-
waiting for the journalcopy of the remaining transactions to the standby
-
allowing the standby to stop the master
-
|
High Availability |
|
|---|---|
| The high availability standby server can become the new master server |
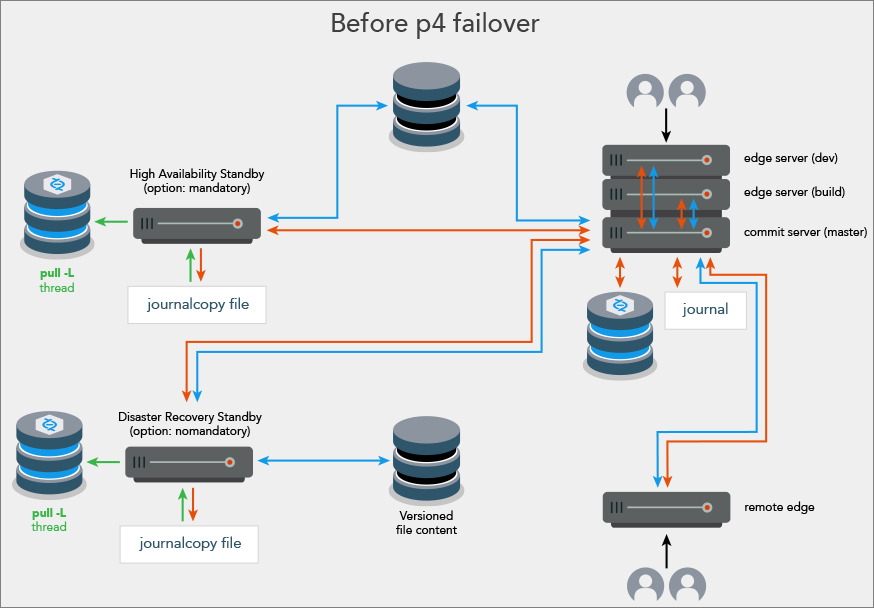
|
| p4 failover defaults to the master server participating while high availability standby is preparing to take over as the new master server |
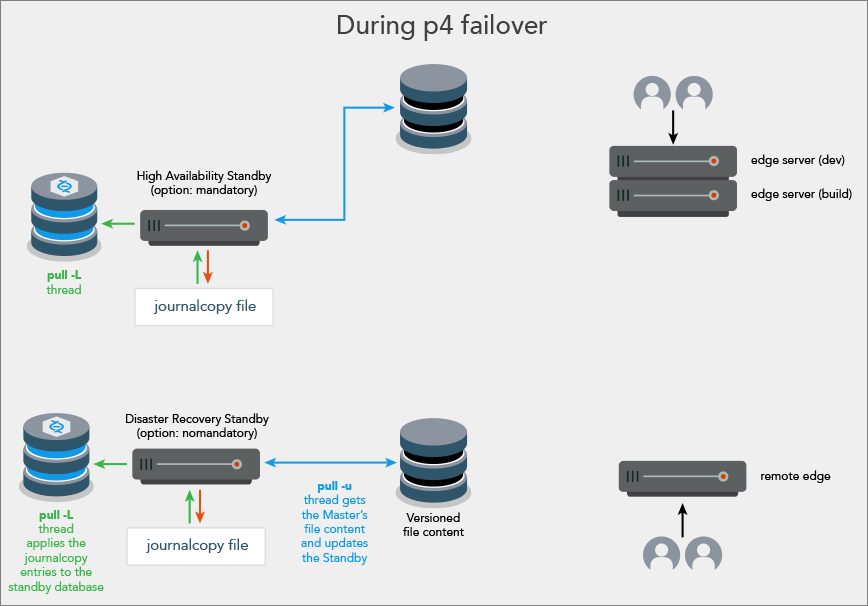
|
| The former high availability standby has become the new master server |
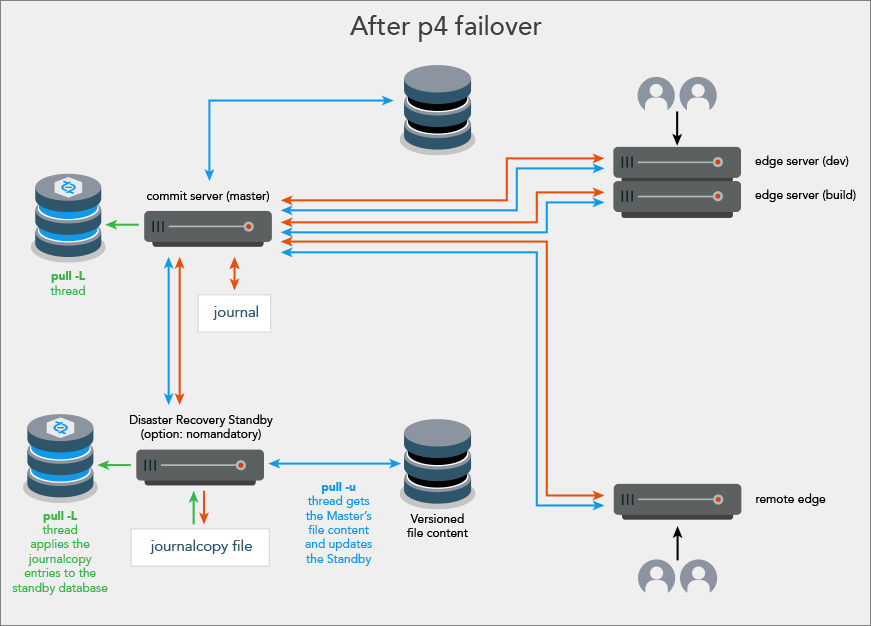
|
If the master does not participate
If the master server does not participate in the failover, a check is made to ensure that the standby server to which failover is to occur has the mandatory option set. Without the participation of the master server, failing over to a mandatory standby server is required to ensure that the other replicas remain consistent with the new master server after failover. Consistency is assured because during production operations, metadata must be journalcopy'd by all mandatory standby servers before that metadata is replicated to the other replicas.
Consider deploying one or more mandatory standby servers that are local to the master server because journalcopy performance of the mandatory standby servers that are remote can affect the production replication to the other replicas.
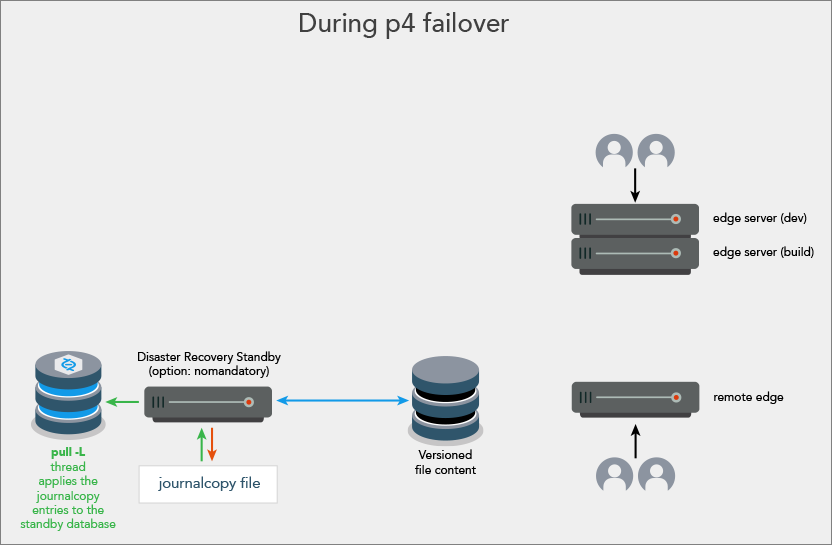
Disaster Recovery (DR)
- Typical use case: due to a sudden catastrophe, the master server (and any HA standbys) are unable to operate.
-
Contact support for assistance with failing over to a non-mandatory standby server when the master server is inaccessible.
Consistency of the downstream replicas is assured for failing over when:
- the master server participates, in which case:
- the standby server does not need to be a
mandatorystandby - the standby server's journalcopy, pull -L, and pull -u threads are an integral part of the failover
- the standby server does not need to be a
- the master server does not participate and the standby server is a
mandatorystandby, in which case only the standby server's pull -L thread is an integral part of the failover
|
Disaster Recovery |
|
|---|---|
| The disaster recovery standby server can become the new master server |
|
| If a catastrophic failure of the data center occurs, both the master server and the high availability standby server might be unavailable |
|
| The disaster recovery standby server has become the new master server |
|
Prerequisites for a successful failover
-
The p4 failover command must be run on a server of Type standby or forwarding-standby. See the Standby and forwarding-standby topic.
- The standby (or forwarding-standby) server must be appropriately licensed for its new role following the failover. Fill out the form at Helix Core Duplicate Server Request.
-
Make sure that replica database is an exact match of the master database by using the p4 journaldbchecksums command. If the results indicate
DIFFERoremptyinstead ofmatch, reseed the replica to ensure data integrity across the replicated installation before you attempt to perform the failover operation. To learn more, see How to reseed a replica server in the Perforce Knowledge Base. - Make sure that monitoring (p4 monitor) is enabled for the new standby server (former master or Commit Server).
Monitoring must be enabled at server startup of the standby prior to running the p4 failover command. This is because the monitor subsystem is used to terminate the journalcopy, pull -L, and pull -u threads during the failover sequence.
-
Open the server spec for each standby and forwarding-standby server. In the ReplicatingFrom field, enter the
serverIDof the server from which the standby server is journalcopy'ing. - If an Edge Server is being failed over, the service user of the Edge Server should be logged into the commit (or master) server using the file specified by the P4TICKETS variable that is defined for the standby of the Edge Server. For example, issue the following command on the standby server that will become the new master:
$ export P4TICKETS=directory/.p4tickets$p4 -p master:port -u serviceuser login
If you plan to use Failback after failover to restore the original master, we also recommend that a DNS alias point to the IP address of the standby server .
To be prepared in case you might need to decide whether a failover operation is necessary, consider monitoring a target server by setting up Triggering on heartbeat (server responsiveness).
Failover to a standby or forwarding-standby
Failing over to a dedicated standby is generally faster than failing over to a forwarding-standby. For situations where failover completion is less time-critical, you might want to consider a forwarding-standby. See "standby" and "forwarding standby" in p4 server in the Helix Core Command-Line (P4) Reference.
High availability with the mandatory server specification option
A high availability standby within an existing installation should not be initially deployed as mandatory.
To deploy standby servers with minimal interruption to replication, make sure the journalcopy thread of the new standby server is caught up with the server from which is it journalcopying BEFORE you set the standby to mandatory. Follow this process:
- Deploy the standby with the default, which is nomandatory
- To monitor the progress of the standby's journalcopy, on the server from which the standby is journalcopying, invoke p4 servers -J
In this example, we have invoked p4 servers -J on master, and we see that standby2 has 400, which does not yet match the 682 value on master:

Later, again on master, we invoke p4 servers -J to see that standby2 has progressed to 682, which matches master and indicates that standby2 has a current journalcopy.

- Change the server spec for standby2 to specify mandatory
On the innermost master server, in the server specification for standby2, under Options, mandatory is now appropriate for a standby (or forwarding-standby) server. This option ensures that no replica has metadata that has not been copied to the journalcopy of all mandatory standby (or forwarding-standby) servers.
If the master were unavailable, standby1, which is not a mandatory standby, could not be used for failover.
If the master is available, all four of the standbys could be used for failover.
If the server from which failover is to occur is not participating in the failover (because the master is unavailable or the -i option causes the master to be ignored), the p4 failover command returns an error if it is running on a standby (or forwarding-standby) server that is not properly configured with the mandatory option.
Disaster recovery with the nomandatory server specification option
For disaster recovery failover, the remote standby typically has a server specification with the Option field set to the default value, which is nomandatory. This is because the journalcopy performance of a mandatory standby can affect the speed of replication to the replicas of the master.
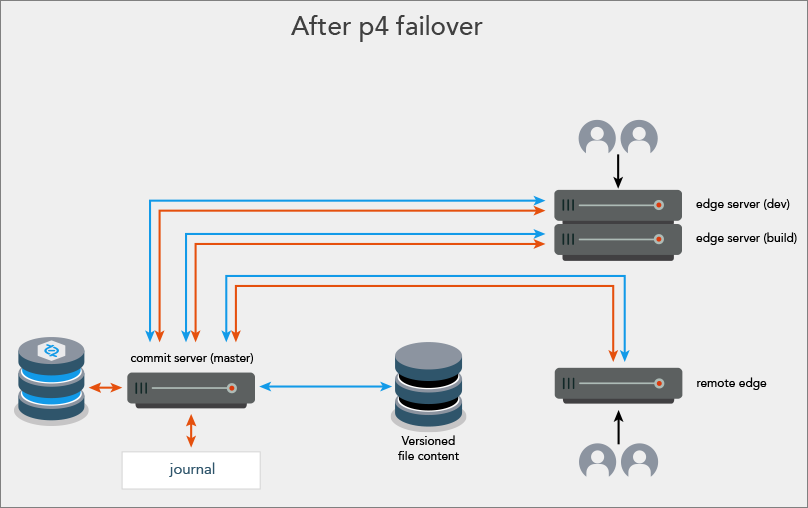
After failover
After the failover process is complete:
-
The former standby server is now the new master server.
-
The standby server’s spec in the new master server’s metadata is left intact, except that it is set to
nomandatory. This prevents transactions from being stalled while waiting for the journalcopy of those transactions to a standby server that no longer exists. Also, the spec can be used when the former master server is configured as a new standby server. -
The master server is stopped if the master server participated in the failover.
Potential data loss
If the master participates
-
Any commands that were not completed when failover began might need to be executed again on the new master server.
- There should not be any data loss.
If the master does not participate
- Standby is mandatory
-
Any commands that were not completed when failover began might need to be executed again on the new master server.
- The transactions that were done directly on the master prior to the failover that had not yet been journalcopy'd to the standby being used for the failover will be lost.
-
To minimize data loss, the standby used for the failover should be the standby that was the most current with the master at the time of the failover. Typically, this is the standby that is in the same rack with the master.
-
The downstream replicas are consistent with the new master server.
-
The downstream replicas will not have data loss relative to the new master server.
-
Failover process
The Failover feature allows the super user to do the following.
|
1.
|
Get a report of whether conditions look good for a successful failover. Warning
If the report indicates that the existing master server is still accessible and ignoring that server has been requested with the -i option, this could result in two separate servers, each of which is unaware of the other. This "split-brain" situation can produce inconsistencies that compromise the integrity of your data. |
||||||
|
2.
|
Initiate the failover process on the standby server.
|
||||||
|
3.
|
Monitor the steps that are reported during the process. If the failover process encounters an error, the process is designed to inform the superuser and to stop the failover process so that corrective action can be taken and a new attempt can occur. If an error is encountered after the standby server has stopped the master server, the standby server will not restart the master server. |
||||||
|
4.
|
After the completion of a successful failover,
|
||||||
|
5. |
You have the option of performing a Failback after failover. |
Configurables affected
The failover process:
- makes no changes to the configurables on the original master server
- can make changes to the following for the new master so that the values are appropriate for the new environment:
Configurables and Edge Server
When failing over to a standby from an edge (or other replica) server, the updated configurables for the Edge Server will need to be manually changed on the Commit Server. This is because the update of the configurables cannot be propagated back to the commit (or upstream) server automatically, given that the Edge Server might, or might not, be participating in the failover.
If p4 failover cannot be used
The p4 failover command is not supported for the disaster recovery scenario in which the only standby servers remaining use the nomandatory option. At a remote disaster recovery site, it is generally recommended that the standby server use the nomandatory option.
Network latency and bandwidth to the server from which the standby server is journalcopy'ing might delay journalcopy operations to a standby server at a remote disaster recovery site. If the journalcopy operations are delayed and that standby server uses the mandatory option, replication to other replicas could be delayed. This is because each transaction must be journalcopy'd by all standby servers using the mandatory option before the transaction can be replicated to other replicas.
Metadata consistency issue with nomandatory
Using the nomandatory option avoids the potential performance issue mentioned above. However, if the standby server at a remote disaster recovery site uses the nomandatory option, some transactions might have been replicated to the other replicas but not yet journalcopy'd to the standby server at the remote disaster recovery site.
In such a case:
-
The standby server using the
nomandatoryoption might lack metadata transactions that are present in the other replicas. -
The other replicas must therefore be reseeded back to a consistent point rather than using the
p4 failovercommand.
Reseeding
The following only applies for a true disaster in which none of the remaining standby servers use the mandatory option.
-
Use the standby server as a basis for reseeding the other replicas. Reseeding the other replicas is a supported recovery method when the standby server is using the
nomandatoryoption. (See the Perforce Knowledge Base article on How to reseed a replica server.) -
After reseeding the replicas from a checkpoint (or dump) taken from the standby server using the
nomandatoryoption, that standby server can become the new master because the replicas have been reseeded from its metadata. The metadata of the replicas is now consistent with that of the standby server. After changing the server ID to that of the master server, that server will become the new master server and use the master's configuration when it is started.





