How remote depots work
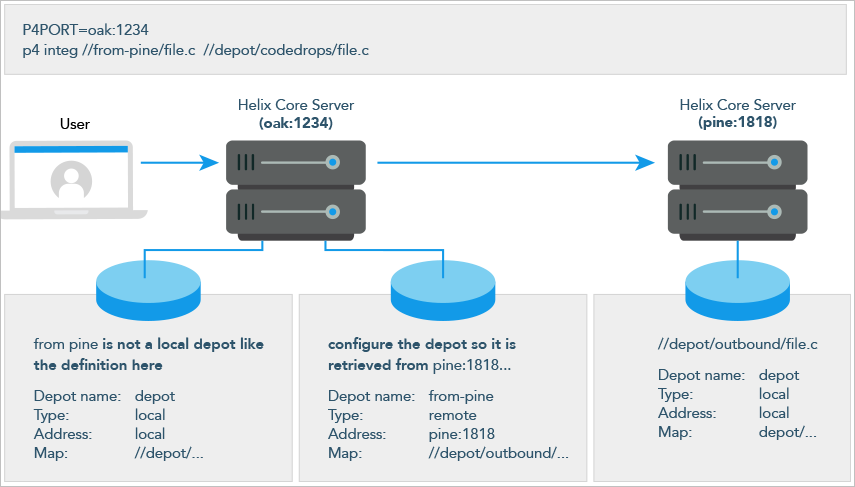
The following diagram illustrates how Helix Server applications use a user’s default Helix Core Server to access files in a depot hosted on another Helix Core Server.
In this example, an administrator of a
Helix Server
at oak:1234 is retrieving a file from a remote server at
pine:1818.
Although it is possible to permit individual developers to sync files from remote depots into their client workspaces, this is generally an inefficient use of resources.
The preferred technique for using remote depots is for your organization’s build or handoff administrator to integrate files from a remote depot into an area of your local depot. After the integration, your developers can access copies of the files from the local depot into which the files were integrated.
To accept a code drop from a remote depot, create a branch in a local depot from files in a remote depot, and then integrate changes from the remote depot into the local branch. This integration is a one-way operation; you cannot make changes in the local branch and integrate them back into the remote depot. The copies of the files integrated into your Helix Server installation become the responsibility of your site’s development team; the files on the depot remain under the control of the development team at the other Helix Server installation.
Restrictions on remote depots
Remote depots facilitate the sharing of code between organizations (as opposed to the sharing of development within a single organization). Consequently, access to remote depots is restricted to read-only operations, and server metadata (information about client workspaces, changelists, labels, and so on) cannot be accessed using remote depots.





