Blog
June 6, 2025
5 ETL Pipeline Best Practices (And What Yours is Missing)

Data Management,
Security & Compliance
When searching for ETL pipeline best practices, you will find some common themes: ensuring data quality, establishing consistent processes, and automating out repetitive tasks. There’s a reason these are recommended over and over: they help establish reliable, efficient, and scalable workflows.
But one thing that isn’t often emphasized is the importance of implementing consistent, scalable compliance efforts — specifically by using data masking.
In this blog, we will explore 5 best practices for building successful ETL pipelines at the enterprise level. Then, we will dive into why data masking is so intimidating, yet important. Finally, we will review one solution for implementing data masking at scale.
Back to topUnderstanding ETL Pipelines in the Enterprise Environment
First, let’s cover some basics: what is an ETL pipeline, how have approaches to ETL pipelines changed over time, and how are they used at enterprise scale across industries?
First, What is an ETL Pipeline?
An Extract, Transform, Load (ETL) pipeline is the backbone of modern data integration. It gathers data from multiple sources, converts it into a unified format, and loads it into a central repository, like a data warehouse or lake.
One of the key capabilities of ETL pipelines is that they handle data delivery across homogeneous systems (like SQL databases) as well as heterogeneous ones (like cloud-based APIs and on-premises environments). Most businesses use many different systems for data, so ETL pipelines make sure their systems can share data smoothly.
ETL pipelines ensure data is consolidated and easy to access across the organization (by the right people). They ensure data is primed for analytics, enabling better data-driven decision making.
Traditional ETL Pipelines vs. Modern Approaches
Traditional ETL pipelines follow a rigid process: Data is pulled from sources, transformed in a centralized server (often with heavy scripting or ETL tools), and then loaded into a data warehouse. This process worked well when data volumes were smaller and updates were nightly or batch-based.
Modern ETL pipelines are cloud-native, can support real-time access to data, and give teams more control and flexibility. They make working with data faster, easier, and more reliable than traditional pipelines.
Use Cases for ETL Pipelines Across Industries
ETL pipelines aren’t just for data engineers in the back room anymore. They're the quiet engine behind smarter decisions, faster insights, and seamless operations across every major industry.
Here are some ways ETL pipelines are used at enterprise scale across industries:
Healthcare
Hospitals and clinics often run on multiple systems that don’t talk to each other. ETL pipelines help bring together Electronic Health Records (EHRs), lab results, and patient histories into one clean dataset.
For example, a hospital may use ETL to aggregate patient data across departments. This is done to improve diagnostics, personalize treatment, and even feed into predictive models for disease outbreaks.
Financial Services
In the financial world, timing and accuracy are everything. ETL pipelines are critical for bringing together transactional data from ATMs, mobile apps, and card swipes. Banks rely on these pipelines to spot unusual patterns and comply with strict reporting rules. Every time a transaction looks suspicious, there's probably an ETL job that helped flag it.
Retail
Modern retailers collect data from POS (Point Of Sale) systems, mobile apps, email campaigns, and website clicks. ETL pipelines stitch all this data together to paint a full picture of customer behavior. For instance, an online retailer can use ETL to constantly update product recommendations, optimize pricing, and adjust inventory based on what people are browsing and buying in real time.
Plus, think about what goes into delivering a package across the world: weather updates, GPS data, driver check-ins, warehouse scans, and so on. Delivery companies use ETL to merge all this data so they can track shipments in real time and predict delays before they happen.
How ETL Pipelines Make or Break Success in AI and Analytics
For many organizations, ETL pipelines are the backbone of successful AI and analytics initiatives. But without the right safeguards in place, sensitive data can enter AI environments and become impossible to remove.
In his eBook “AI Without Compromise,” Perforce Delphix’s resident AI and data security expert Steve Karam dives into the critical challenges leaders face today in balancing data privacy, regulatory compliance, and AI innovation. Learn how unified compliance frameworks, irreversible data masking, and scalable solutions can help enterprise teams safeguard sensitive information while accelerating AI initiatives.
Back to top5 ETL Pipeline Best Practices for Enterprises
1: First and Foremost, Data Quality is Everything
In working with customers, a common challenge I see is underestimating the effort required for data quality early in the ETL process. Many teams focus on transformation logic but overlook foundational profiling and cleansing, leading to costly rework downstream.
Data quality is the foundation upon which all success is built. When organizations prioritize data quality from the start, they see faster insights, better decision-making, and fewer disruptions in analytics workflows. Messy or inaccurate data can significantly slow down your processes (not to mention invalidate any insights you gain from it).
For enterprise organizations, the stakes are even higher. With the vast amounts of data your organization processes daily, small quality issues can balloon into widespread inefficiencies and costly errors.
To ensure optimal data quality, enterprises should implement robust profiling, cleansing, and validation practices:
- Data profiling helps identify irregularities and inconsistencies in datasets by analyzing metadata and content. This creates a clear picture of the dataset’s integrity.
- Data cleansing removes duplicates, corrects errors, and fills in missing values to ensure consistency and accuracy.
- Data validation ensures incoming data meets quality benchmarks through rules and automated checks. It prevents bad data from entering the pipeline.
These steps ensure that your ETL pipeline delivers clean, accurate, and actionable data.
2: Automate Workflows for Maximum Efficiency
One of the most essential best practices for ETL pipelines is automating repetitive tasks. Human error causes delays, inconsistencies, and higher operational costs. For enterprises managing vast amounts of data, even small errors can significantly impact productivity and decision-making.
Automation ensures consistency and reliability at scale. Using orchestration tools (like Azure Data Factory, Microsoft Fabric Pipelines, Databricks Workflows, Apache Airflow) allows enterprises to schedule and manage their ETL workflows seamlessly.
Embedding automation into error handling, monitoring, and testing further strengthens workflows. For example, automated error handling detects and resolves data pipeline issues in real-time. Monitoring tools provide visibility into pipeline performance. And automated testing ensures data integrity from start to finish.
Many customers we've worked with highlight that introducing automation into their ETL pipelines dramatically reduces time spent on firefighting. One enterprise reported a 40% drop in data-related incidents after implementing automated error handling and monitoring. Teams went from reactive troubleshooting to proactive optimization, improving both trust in data and delivery timelines.
3: Optimize Pipeline Performance
Ensuring your ETL pipeline performs optimally is key to handling data efficiently. Here are a few ways to boost performance:
- Parallel processing executes multiple ETL tasks simultaneously.
- Caching minimizes how often data must be pulled in from external data sources by storing frequently-used data in a fast-access layer.
- Incremental data updates process only new or modified data, saving resources.
4: Implement Cost Management
To ensure sustainable ETL pipelines at the enterprise level, cost management is critical. Some key strategies for minimizing cost without compromising efficiency or quality include:
- Optimize cloud storage: Manage cloud costs by compressing data and use tiered storage to cut cloud costs. Move rarely used data to cheaper options like cold storage.
- Reduce licensing fees: Consider scalable, pay-as-you-go platforms.
- Use serverless and auto-scaling compute: Choose serverless ETL options (like Azure Data Factory Pipelines) to eliminate idle compute costs. Enable auto-scaling to adjust resources based on workload dynamically.
- Optimize data processing frequency: Avoid over-processing. Run pipelines only when necessary. Batch low-priority jobs during off-peak hours.
5: Build In Robust Security and Compliance Measures
Protecting sensitive data isn’t just good practice; it’s essential for maintaining compliance, preventing sensitive data sprawl, and safeguarding your customers' information. For enterprise organizations, the stakes are even higher. Mismanaging sensitive data can lead to costly regulatory fines, reputational damage, and business disruptions.
To ensure enterprise-grade security, it’s critical to protect data before it ever enters your ETL pipelines. Some ways to do this include:
Data Classification
Before you can protect sensitive data, you need to know what it is and where it lives. Data classification helps categorize data by its level of sensitivity (public, internal, confidential, regulated) to inform decisions about masking, encryption, and access.
Immutable Audit Logging
Log every access, transformation, and movement of data as it enters and flows through ETL pipelines. Immutable audit logs help with compliance, forensics, and early detection of unauthorized access or anomalies.
Secure Data Transfer Channels
Ensure data is moved through secure APIs, VPNs, or private links. Avoid using unsecured file transfers or legacy ingestion methods where possible.
Zero Trust Architecture
Apply Zero Trust principles to data movement. Treat every system and user as potentially untrusted. Require authentication, authorization, and continuous validation before granting access to data.
Static Masking
Static data masking ensures that sensitive data is irreversibly anonymized long before it reaches downstream systems, significantly reducing data exposure and security risks. This process replaces original data with fictitious yet realistic values, maintaining the utility of the dataset for development, testing, or analytics without compromising confidentiality. It is especially valuable in non-production environments, where strict data access controls are often less rigorously enforced.
Back to topWhy Consistent, Scalable Compliance is So Critical at the Enterprise Level
Why should enterprise leaders care about implementing consistent, scalable, compliant data delivery solutions?
In short: because it allows you to more easily meet regulatory requirements, ensure operational resilience, and build trust.
Ensure Regulatory Compliance
Consistent, scalable compliance lets you avoid costly fines by adhering to regulations like GDPR, HIPAA, and CCPA.
It also lets you safeguard your organization’s reputation by mitigating legal risks and maintaining transparency. Build trust with regulators, customers, and stakeholders through compliant processes.
Boost Operational Efficiency
Scalable compliance is also important in streamlining ETL processes across multiple systems, reducing complexity and overhead.
Stay ahead of evolving regulations and technology with agile, future-ready solutions.
Enable Scalability and Flexibility
Seamlessly handle varying workloads by scaling data pipelines up or down. Deliver masked, compliant data to diverse environments without disruptions.
Static masking empowers enterprises to balance compliance, efficiency, and scalability, ensuring a robust and future-proof data pipeline.
Back to topWhat Your Enterprise ETL Pipeline May be Missing: Consistent Masking
Data masking serves as a bulwark against the rising tide of data insecurity, ensuring data is secure when it’s loaded into its final destination.
But for masking to be effective at the enterprise level, a scalable solution that can mask consistently across sources is a must. Whether for analytical or transactional systems, data must be masked consistently so it’s usable across the entire data estate.
Most organizations are using data masking in their ETL pipelines in some capacity — often with home-grown scripts or manual data masking processes that simply cannot be consistent or scalable.
Some shy away from data masking completely due to its perceived complexity. Leaders are afraid they will not be able to implement it without breaking downstream processes that rely on original data formats or values. There is no single unified solution that can integrate with tons of datasets supported by ETL platforms.
And many organizations prioritize performance and speed over security, assuming masking will slow down ingestion or transformation.
But you don’t have to choose between speed and security.
Back to topSimplify and Speed Up Masking in Azure ETL Pipelines with Delphix
For organizations using Microsoft Azure for their ETL pipelines, Perforce Delphix offers a solution to simplify and speed up data masking: Delphix Compliance Services.
Built in partnership with Microsoft, this SaaS solution seamlessly integrates with Azure ETL pipelines in Microsoft Fabric, Azure Data Factory, and Azure Synapse Analytics — empowering organizations to achieve unparalleled levels of data security and regulatory compliance.
Delphix Compliance Services has two primary components:
Automated Sensitive Data Discovery
Delphix Compliance Services automates the process of identifying sensitive data within your source datasets. It automatically matches discovered data to relevant compliance rules and recommends appropriate masking strategies. It also seamlessly integrates with third-party data classification and discovery tools. This lets you import classification results into masking workflows with ease.
Automated Data Masking
Delphix Compliance Services automatically replaces sensitive data with realistic yet fictitious values using regulation-specific masking algorithms. Following an Extract, Mask, Load (EML) pipeline, Delphix ensures compliance by delivering masked data to target systems, regardless of whether they are homogeneous or heterogeneous environments. The result is production-ready, compliant data that is secure yet fully functional for development, testing, or analytics.
Before Delphix Compliance Services for Azure:
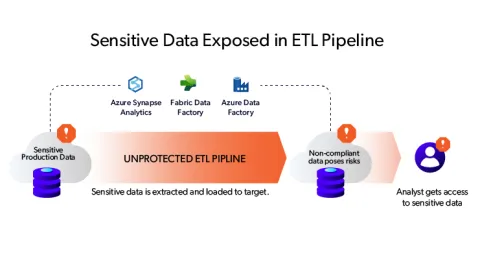
After Delphix Compliance Services for Azure:
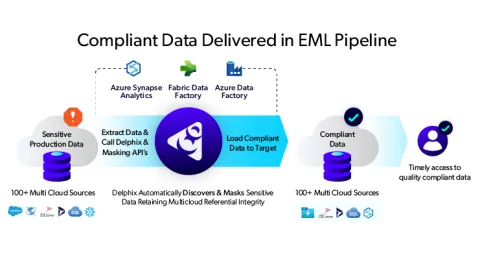
Learn more about Delphix Compliance Services
Back to topEnsure Scalable, Compliant ETL Pipelines for AI and Analytics
If you’re like most tech leaders, AI is a top priority — and a top concern. Data used in AI initiatives must be compliant. And for the best outcomes, it also has to be high-quality, as AI requires clean, well-structured, and consistent data. Many leaders feel it’s impossible to deliver compliant, high-quality data quickly.
With AI and analytics solutions from Perforce Delphix — including Delphix Compliance Services for Azure and Fabric — there are no trade-offs: only high-quality, compliant data delivered fast.
Contact Us to Explore AI Solutions
Talk to our experts to discover how Delphix can speed up compliance, enhance data security, and ensure high-quality data for your enterprise AI initiatives.