Blog
April 22, 2026
What is Data Masking? Best Practices for Meeting Enterprise Compliance Standards

Data Management,
Security & Compliance
Data masking protects sensitive information by replacing real data with realistic, fictitious values. It’s essential for securing data, reducing breach risks, and meeting compliance standards.
Let’s explore the fundamentals of data masking, its importance, when it's needed, and some real-world examples of how it’s used.
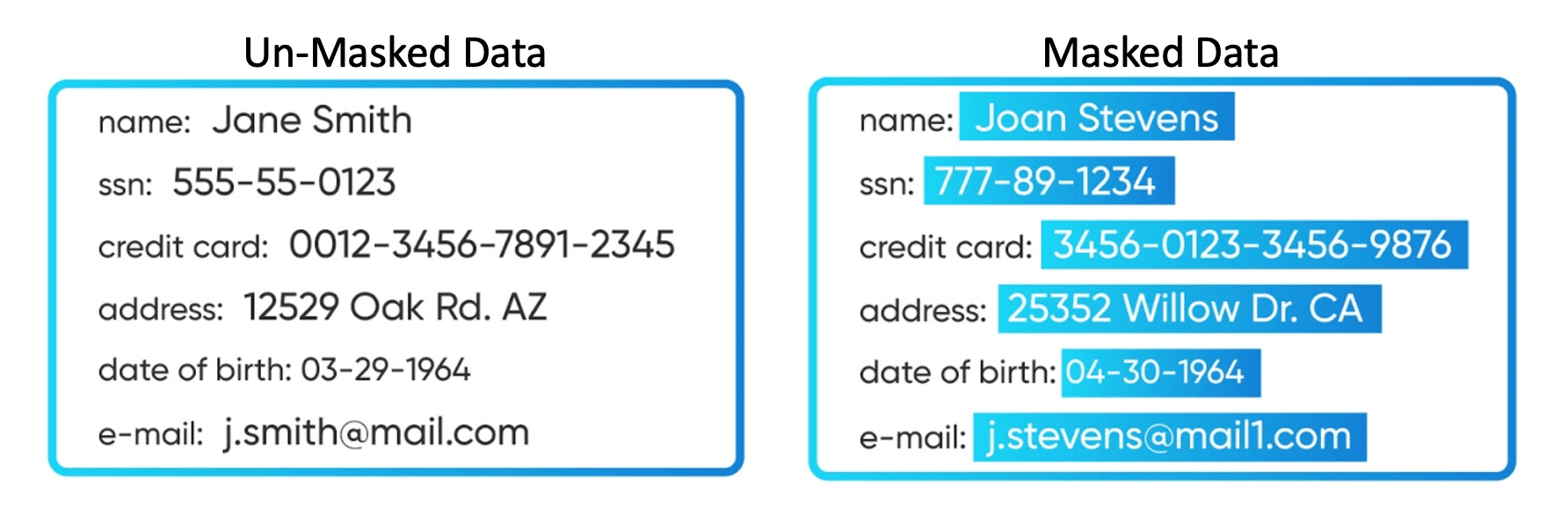
Back to topWhat is Data Masking?
Data masking protects sensitive data by replacing the original value with a fictitious but realistic equivalent.
Data masking safeguards the privacy of an organization’s data, and more importantly, their customers’ data. It helps businesses comply with data regulations and reduces the risk of data breaches.
Data masking is an umbrella term for data anonymization, pseudonymization, redaction, scrubbing, or de-identification. (More on this later when we go over types of data masking.)
 Back to top
Back to top
What Data Needs to Be Masked?
Sensitive data, when used outside of production environments, should be masked. This includes:
- Personally identifiable information (PII): Name, address, email address, phone number, Social Security number, date of birth, etc.
- Government or legal identifiers: Driver's license numbers, passport numbers, tax IDs, etc.
- Financial information: Account numbers, card numbers, credit scores, transactions, etc.
- Protected health information (PHI): Patient records, diagnoses, insurance information, etc.
- Authentication and security credentials: Passwords, API keys/tokens, encryption keys, etc.
What are the Most Common Types of Data Masking?
Data masking comes in several forms, each suited to different use cases for protecting sensitive data in non-production environments. Learn how these types compare to each other and what scenarios each would be most effective for.
Data Masking vs. Data Encryption
Data masking and data encryption both play crucial roles in protecting sensitive data, but they serve different purposes. The difference between data masking and encryption is encryption scrambles data, making it readable only with a key. On the other hand, masking replaces data with realistic but fake values that can’t be reversed.
Masked data preserves relationships and logic, making it ideal for testing, development, and analytics. For non-production use cases, data masking offers more value by enabling secure, compliant innovation without exposing real information.
Data Masking vs. Data Anonymization
Data anonymization, in contrast, encompasses broader approaches like redaction, tokenization, and aggregation to remove or transform PII. While anonymization aims to prevent reidentification, it does not guarantee the same referential integrity or practicality for testing as data masking.
Synthetic Test Data vs. Test Data Masking
Synthetic test data is entirely artificial, making it ideal for scenarios where real data is unavailable or access is restricted by compliance. The key distinction between it and test data masking is that synthetic data is generated from scratch, while masked data is a realistic transformation of actual production data.
Explore the different types of data masking in detail >> Data Masking Methods & Techniques: The Complete Guide
Back to topWhat Does the Data Masking Process Look Like?
Here's the data masking process in a few steps:
- Identify the Need for Data Masking:
- Understand that data masking secures sensitive data in non-production environments (e.g., development, testing, analytics, AI) to mitigate risks of breaches and ensure compliance with privacy laws like GDPR, CCPA, and HIPAA.
- Discover Sensitive Data:
- Scan production sources with a data masking tool and identify sensitive information such as names, addresses, credit card numbers, Social Security numbers, and health data.
- Apply Data Masking Policies:
- Leverage a library of predefined policies or create custom ones to comply with relevant laws and business needs.
- These policies use masking algorithms to irreversibly transform sensitive data into realistic but fictitious equivalents.
- Leverage a library of predefined policies or create custom ones to comply with relevant laws and business needs.
- Customize Data Masking Rules:
- Tailor data masking algorithms to specific requirements, such as keeping masked zip codes within a certain distance of the originals or ensuring masked dates of birth remain within a specific range.
- Ensure Data Functionality:
- Maintain production-like quality and preserve relationships in masked data so it remains fully functional for accurate development, testing, and analysis.
- Scale for Any Data Size:
- Apply data masking to datasets ranging from small relational databases to massive analytical sources with billions of records.
- Maintain Compliance and Security:
- Ensure that all processes align with privacy laws and security standards, allowing businesses to innovate without compromising compliance.
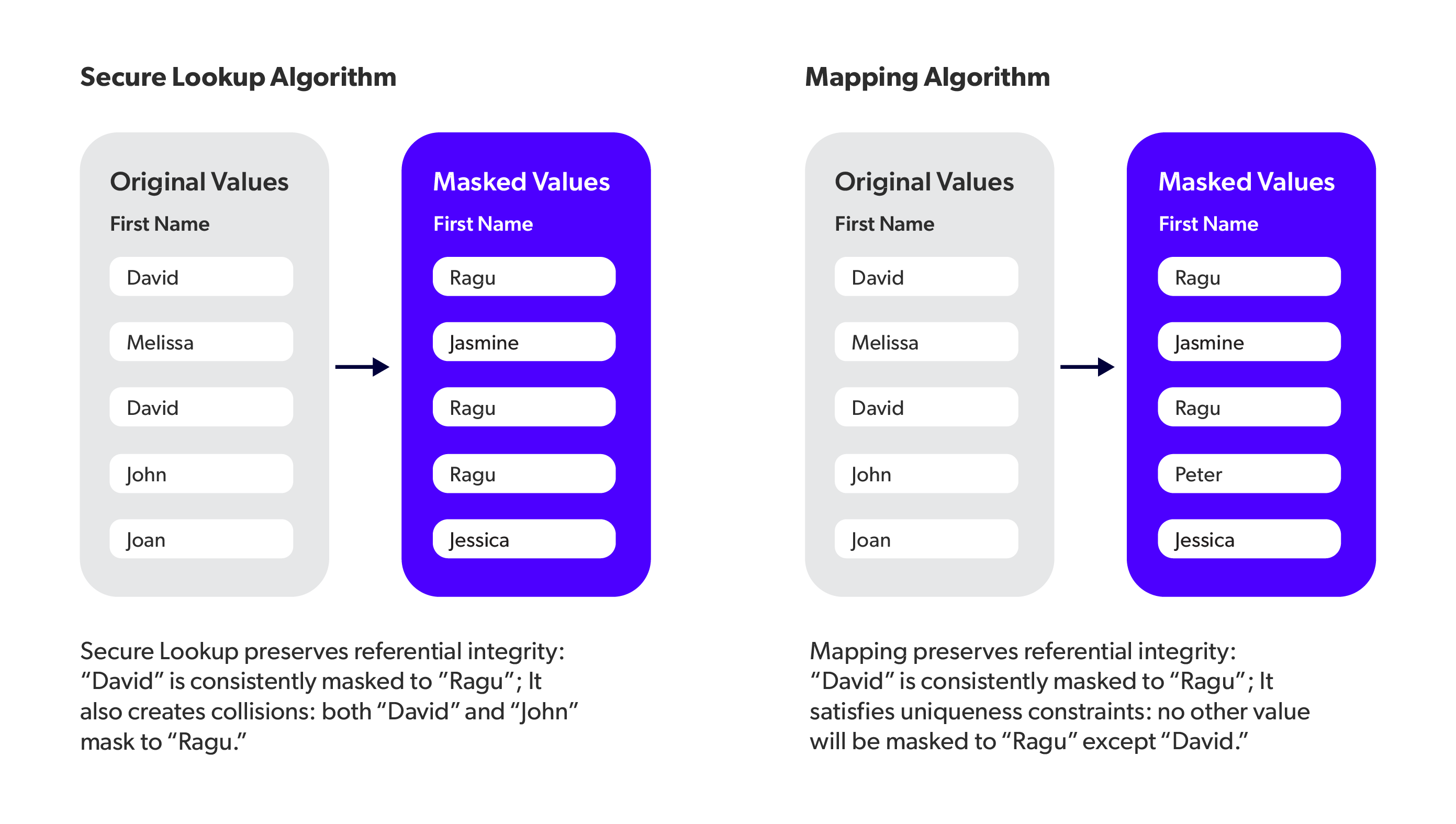
Examples of Data Masking Algorithms
Here's what a data masking algorithm from Delphix looks like. (For more specifics, check out our Technical Guide to Data Masking with Perforce Delphix.)
WEBINAR
How Do You Mask with Perforce Delphix?
See how data masking can made easy with Delphix, as experts Ross Millenacker and Bob Patten show it in action during their recent webinar.
Why is Data Masking Important?
The vast majority of sensitive data in an enterprise exists in non-production environments used for development and testing functions. Non-production environments represent the largest surface area of risk in an enterprise, where there can be up to 12 copies for non-production purposes for every copy of production data that exists. To test adequately, realistic data is essential. However, using real data is a considerable data security risk.
A robust data masking solution eliminates the risk of exposing sensitive data. It also helps business comply with data privacy regulations.
By following PII data masking best practices, companies can move data fast to those who need it, when they need it.
Example: Data Masking in the Healthcare Industry
One healthcare company I worked with needed to offload part of their data analytics work to an offshore team in India. The challenge was that the datasets contained PII — names, social security numbers, and transaction histories — which couldn’t legally or ethically cross U.S. borders without proper protection.
Initially, they delayed sharing the data while legal and compliance teams debated redaction vs. anonymization. This slowed down project timelines and frustrated the offshore team, who were ready to start.
We helped them implement data masking to de-identify PII data. The masked data retained its analytical value but was no longer traceable to individuals. Once this was in place, they could confidently share data offshore within minutes and stay fully compliant with U.S. data residency laws.
That experience made it clear: data masking isn’t just about protecting information; it’s about keeping business moving at the speed it needs to.
Back to topWhat is Data Masking Needed For? Real-World Industry Examples
Sensitive data masking is a vital practice across multiple industries. Here are some examples of data masking benefits in each:
Finance
Banks and financial services companies manage large sets of sensitive data, including account numbers, credit scores, transactions, and social security numbers. Data masking helps protect customer information from internal misuse. It also supports compliance with stringent regulations like PCI DSS and GDPR.
Healthcare
Healthcare organizations handle high volumes of PHI. Documents that contain PHI include patient records, diagnoses, and insurance details. Masking is necessary to meet HIPAA requirements. It ensures that real patient data isn’t exposed in test, development, or analytics environments.
Retail
Retailers process customer names, addresses, payment information, and purchase history. Masking is crucial during the development or testing of e-commerce platforms because it prevents leaks of or unauthorized access to this data. It’s an important ingredient in meeting compliance as well as maintaining consumer trust.
Back to topData Masking Best Practices to Keep in Mind
Take a look at these data masking best practices and how they can support your organization:
- Maintain a comprehensive inventory of sensitive data: Establish and continuously update a centralized inventory of sensitive data assets. To support effective monitoring, auditing, and masking enforcement, this log should include:
- All entities.
- Confidence score.
- Masking policies.
- Continuously validate the effectiveness of data masking: Regularly test and validate your data masking controls to ensure sensitive data is irreversibly protected while preserving data usability. Validation should include:
- Checks for re-identification risks.
- Consistency across environments.
- Alignment with business use cases.
- Enforce strict governance over masking rules and policies: Clearly define ownership and limit administrative control over data masking rules to a small, authorized group. To ensure masking policies are applied consistently and securely, you can and should implement:
- Role-based access controls.
- Change management procedures.
- Audit trails.
REPORT
2025 Data Compliance Findings: What You Don't Know CAN Hurt You
Enterprise leaders know well how to protect sensitive data with data masking. In our recent State of Data Compliance and Security Report, 95% of the 280 surveyed enterprise leaders cited they use static data masking as a way to ensure data privacy in non-production environments.
Learn about other masking and compliance insights from the perspective of Perforce Delphix experts, as they break down the recent report's findings.
Back to top
Data Masking Requirements Your Solution Should Fulfill
In working with large-scale data environments, a handful of key requirements consistently make the difference between a masking solution that simply exists and one that actually enables secure, usable data at scale. To reap data masking benefits, the solution should have these qualities and components:
Referential Integrity
Referential integrity is critical. Without it, masked data becomes fragmented across systems.
For example, George always gets masked to Elliot consistently across environments valuating, updating, and manipulating datasets in an environment — as well as across multiple datasets. (For example, it preserves referential integrity when you mask data in an Oracle database and a SQL Server database).
In one case with a global retailer, inconsistencies between masked customer IDs across platforms rendered analytics nearly useless until a solution was implemented that preserved relationships across all systems.
Realistic Data
Your data masking technology solution must give you the ability to generate realistic but fictitious, business-specific test data. You want the data to work for testing but to provide zero value to thieves and hackers. The resulting masked data values should be usable for non-production use cases. You can't simply mask names into a random string of characters.
For example, a financial services team once masked birthdates with random values, which unintentionally broke their fraud detection models. Switching to logic that maintained age distributions allowed them to preserve analytical value without compromising privacy.
Irreversibility
Irreversibility is essential, especially when data is shared outside trusted boundaries. The masking algorithms must be designed such that once data has been masked, you can't identify the original values or reverse engineer the masked data. This is especially important when using data to tune AI models, as AI is exceptionally good at finding patterns in data.
Read more >> The AI Compliance Crisis: Are You Prepared?
Extensibility & Flexibility
Extensibility and flexibility come into play when scaling across diverse systems. The number of sources involved in the average enterprise data pipeline continues to grow at an accelerated rate. To enable a broad ecosystem and secure data across sources, your data masking solution needs to work with the wide variety of data sources that businesses depend on.
For example, in a large banking environment, a policy-based approach allowed one masking rule to be applied across 20+ systems. This minimized manual effort and risk.
Repeatable & Automated
Repeatability and automation close the loop. A solution should not require re-engineering with every new dataset or business need.
Masking is not a one-time process. Organizations perform data masking repeatedly as data changes over time. It needs to be fast and automatic while allowing integration with your workflows, such as SDLC or DevOps processes.
Many data masking solutions add operational overhead and prolong test cycles. But with an automated approach, teams can easily identify and mask sensitive information such as names, email addresses, and payment information to provide an enterprise-wide view of risk and to pinpoint targets for masking.
Policy-Based
With a policy-based approach, your data can be tokenized and reversed or irreversibly masked in accordance with internal standards and privacy regulations such as GDPR, CCPA, and HIPAA. Taken together, these capabilities allow businesses to define, manage, and apply security policies from a single point of control across large, complex data estates in real time. Database masking — across your enterprise — is simplified.
⚖️ See which data privacy regulations and requirements data masking can support >> Data Privacy Laws and Compliance: What You Need to Ensure Compliant Non-Production Data
Back to topHow Data Masking Benefits Your Organization
There are many data masking benefits. Your customers want to feel assured that their personal information is safe from bad actors. You also want to be able to safely use data to innovate, provide better experiences, and so on. Data masking guarantees both.
Done correctly, data masking can:
- Protect the content of data while preserving business value.
- Help maintain referential integrity across databases, supporting compliance with privacy regulations and reducing the risk of data breaches.
- Allow organizations to confidently share data in non-production or cloud environments while minimizing exposure to threats — no programming expertise necessary.
Watch the video below to learn more about the benefits of data masking for developers.
Back to top
How Delphix Data Masking Technology Revitalized 3 Enterprises' Data Operations
Organizations across industries choose Perforce Delphix for automated, scalable data masking that accelerates compliant data delivery, protects sensitive information, and streamlines innovation. See how Molina Healthcare, Morningstar, and Choice Hotels improved security and efficiency with Delphix data masking.
Healthcare: Molina Healthcare
Molina Healthcare uses Delphix data masking to automatically secure protected health information (PHI) across thousands of non-production databases, ensuring HIPAA compliance while streamlining development workflows.
By integrating Delphix’s automated masking and provisioning, Molina reduced environment setup times to under ten minutes. They also halved application project schedules and achieved 4PB in storage savings.
Financial Services: Morningstar Retirement
Morningstar Retirement uses Delphix data masking to automate secure test data management and ensure SOC 2 compliance.
By implementing Delphix, Morningstar reduced data provisioning hours by 70%, improved software quality through earlier defect detection, and enabled developers to focus on delivering new features and enhanced security.
Telecommunications: Proximus
Proximus struggled with its data masking, which was inconsistent across teams and had to be repeated over and over again.
Thanks to automated data masking with Delphix, the telecommunications enterprise was able to solve this issue and reduce the time it takes to refresh 60 applications from two weeks down to one weekend.
Get Demo
Automate & Scale Data Masking with Perforce Delphix
Perforce Delphix delivers automated, scalable data masking capabilities. It enables enterprises to mitigate risk, ensure privacy compliance, and accelerate secure innovation across DevOps and AI pipelines. Here’s how:
Advanced Data Discovery
Delphix automatically identifies sensitive information — including names, email addresses, and payment details — with enterprise-wide visibility to accurately assess compliance risk and pinpoint masking targets.
Automated Data Masking
Delphix uses its static data masking solution to irreversibly transform sensitive data into realistic yet fictitious equivalents that preserve business value and referential integrity for development, testing, and AI and analytics pipelines.
Unlike encryption-based approaches, Delphix's automated masking ensures that transformed data cannot be reverted to its original state, providing robust protection for non-production environments.
Scalable Integration & Centralized Control
Extend masking across complex data estates and integrate seamlessly with critical DevOps and compliance workflows. Delphix delivers single-point policy enforcement and governance for all non-production data. It supports a wide range of environments, from mainframe to cloud-native.
Together, these compliance capabilities enable enterprises to:
- Define, manage, and enforce security and compliance policies centrally.
- Reduce sensitive data exposure by up to 77%.
- Accelerate application releases by 2x.
See Data Masking in Action
See for yourself how Delphix gives teams the power to discover and mask sensitive data for privacy compliance, secure innovation, and operational efficiency.