Blog
March 12, 2026
Data Masking vs. Tokenization: Understand the Differences & When to Use What

Data Management,
Security & Compliance,
AI
Data masking vs. tokenization — which should your organization be using to protect sensitive data?
The simplest answer: if you need to easily re-access original data, tokenization is preferable. If you need irreversibly transformed data for development or analytics, masking is the superior choice.
This is especially true when it comes to using data for artificial intelligence. In fact, according to the Perforce Delphix 2026 State of Data Compliance and Security Report, 68% of the 518 surveyed global enterprise leaders are concerned about data leaks in AI and ML development, and 51% worry about personal data being re-identified in these environments.
In this blog, I will explain the specific challenges and strengths for masking vs. tokenization before exploring one solution and its use cases across industries. Let's dive in.
Back to topWhat’s the Difference Between Masking & Tokenization?
On the surface, data masking and tokenization look similar, but their respective approaches and use cases are distinct from each other. To give you a better understanding, let’s go over some quick definitions and key differences between data masking and tokenization.
Data Masking
Data masking is a method that hides sensitive data by replacing it with realistic but fake information. The main benefit is that masked data keeps the same format and usefulness as the original data but doesn't show sensitive information.
This format-preserving masking has become essential for building and testing applications. It lets teams work with realistic data without the risk of exposing sensitive information.
Masking policies convert the original value into something that looks valid and usable, static masking guarantees the real, sensitive data cannot be retrieved. This is what Delphix does.
Data masking changes the value but keeps it readable or realistic. Here, the data is modified but still looks like real data.

Tokenization
Tokenization, on the other hand, is a data protection technique with separation-of-data control. The sensitive value is removed and replaced with a non-sensitive placeholder called a “token,” while the real value lives in a secure vault.
If the vault is well protected, the token itself has no exploitable meaning. While the original value cannot be recovered with data masking, this token vault maps the tokens back to their original values. Only authorized users can access the original data when needed.
The token does not resemble the original value and has no mathematical relationship to it.

The real value is stored in a token vault:

Key Characteristics of Tokenization
- Preserves data format and length.
- Can be reversed. (You can get original values back when authorized.)
- Creates separation between sensitive data and working systems.
- Widely used for PCI DSS compliance and payment data protection.
Understanding the Key Challenges of Masking vs. Tokenization
Before we dive into key considerations when deciding between data masking and tokenization for enterprise environments, let’s cover some of the primary challenges of both methods.
Data Masking Challenges
Maintaining Referential Integrity
Data masking should preserve referential integrity across related database tables. In other words, if a value appears in multiple places, the masked value should remain consistent. If values are not consistent, systems that use this data will break.
Impact on Analytics & Testing
Simply replacing all values with the same placeholder often makes the data useless for analysis. For example, if you mask all customer names as "John Doe," you can't analyze trends based on names or regions.
Tool & Platform Compatibility
Adding home-grown masking solutions often requires custom code or middleware. This added layer of complexity makes systems more challenging to maintain.
Tokenization Challenges
Key Management & Vault Dependency
Tokenization relies on secure, centralized token vaults to store and retrieve token mappings. If a vault goes down, slows down, or isn’t set up correctly, any process that needs real-time access to tokens can fail.
Reversibility & Risk Trade-Offs
Tokenization is designed to be reversible, meaning it allows data to be restored when needed. But this also means access must be carefully controlled to manage who can “de-tokenize” sensitive information. Without strong controls, there's a risk of exposing protected data.
Integration with Legacy Systems
Older systems or reporting tools may not handle tokens well. They may expect data to be in its original format or rely on exact values — like full credit card numbers — for functions such as lookups or validation.
Application Compatibility/Usability
A key challenge of tokenization is reduced data usability. Since tokens are meaningless placeholders, applications may not be able to search, analyze, or process the data without retrieving the original value from the token vault.
Back to topWhen to Use Data Masking vs. Tokenization for Enterprises
Data masking and tokenization have different features, which will inform when you should use one over the other. Check out these features to better understand which will fit your enterprise use cases.
| Feature | Data Masking | Tokenization |
| Data Transformation Approach | Changes the actual data values while keeping the format and statistical properties the same. | Replaces data with a token that points back to the original value stored in a secure vault. |
| Reversibility & Data Access | By design, static masking typically cannot be reversed. This reduces the risk of sensitive data leaks. | Designed to be reversible through the token vault for authorized users. Maintains access to original data, which creates potential exposure points. |
| Implementation Impact on Development Teams | Provides realistic test data without compliance risk. Generally, more straightforward to set up. | Needs additional infrastructure and token management processes. |
| Performance & Scalability | No runtime performance impact with static masking. Scalable across enterprise applications and databases. | Potential performance impact from token lookup operations. Scalable across enterprise applications and databases. |
| Security Reality | Irreversible static masking truly removes the possibility of sensitive data leaks. | Reversible method where underlying data stays intact. Your system security is only as strong as its weakest access point. |
Meeting Compliance Requirements with Masking vs. Tokenization
Regulations like the General Data Protection Regulation, California Consumer Privacy Act, and Health Insurance Portability and Accountability Act do not specifically require you to choose between masking or tokenization. Each organization has unique compliance needs and risk profiles. Your decision should reflect these specific factors.
| Data Requiring Protection | Non-Sensitive Analytical Data |
|
|
How to Choose Data Masking vs. Tokenization for Compliance
Choosing the right data protection method starts with a thorough risk assessment. Begin by analyzing the sensitivity of your data and understanding the regulatory requirements that apply to your industry.
For highly sensitive information, such as medical records or financial data, static masking is often the best option. It minimizes the risk of data exposure by removing identifiable elements permanently — without the risk of re-identification. Our 2026 State of Data Compliance and Security Report found that static masking is considered the most purpose-fit data protection method for providing irreversible protection.
On the other hand, tokenization can be a suitable choice for moderately sensitive data when the ability to retrieve original values is necessary. This method allows for secure re-identification, balancing data accessibility with protection.
Consider your data usage patterns too. If teams need realistic test data but don't require access to the real values, masking is typically a better choice. On the other hand, if business operations rely on retrieving original data values, tokenization may be essential, even though it carries a slightly higher security risk.
Review your compliance obligations carefully. Regulations like GDPR and HIPAA have strict rules about data privacy. Static masking often provides the strongest compliance advantage because it eliminates sensitive data completely.
Back to topMasking vs. Tokenization for AI/ML Development
Did you know AI models can learn sensitive data and find patterns that allow re-identification of anonymized data? Irreversible static masking is critical for AI training data. This method permanently transforms sensitive data while maintaining its analytical usefulness.
To protect sensitive data in AI and analytics environments, you’ll need to learn the three key challenges of safeguarding your organization. Discover the latest best practices in our Delphix eBook.
Back to topSelecting the Right Approach: Data Masking vs. Tokenization
Trying to figure out what approach is best for you? Use this decisioning tree to lead you down the right path.
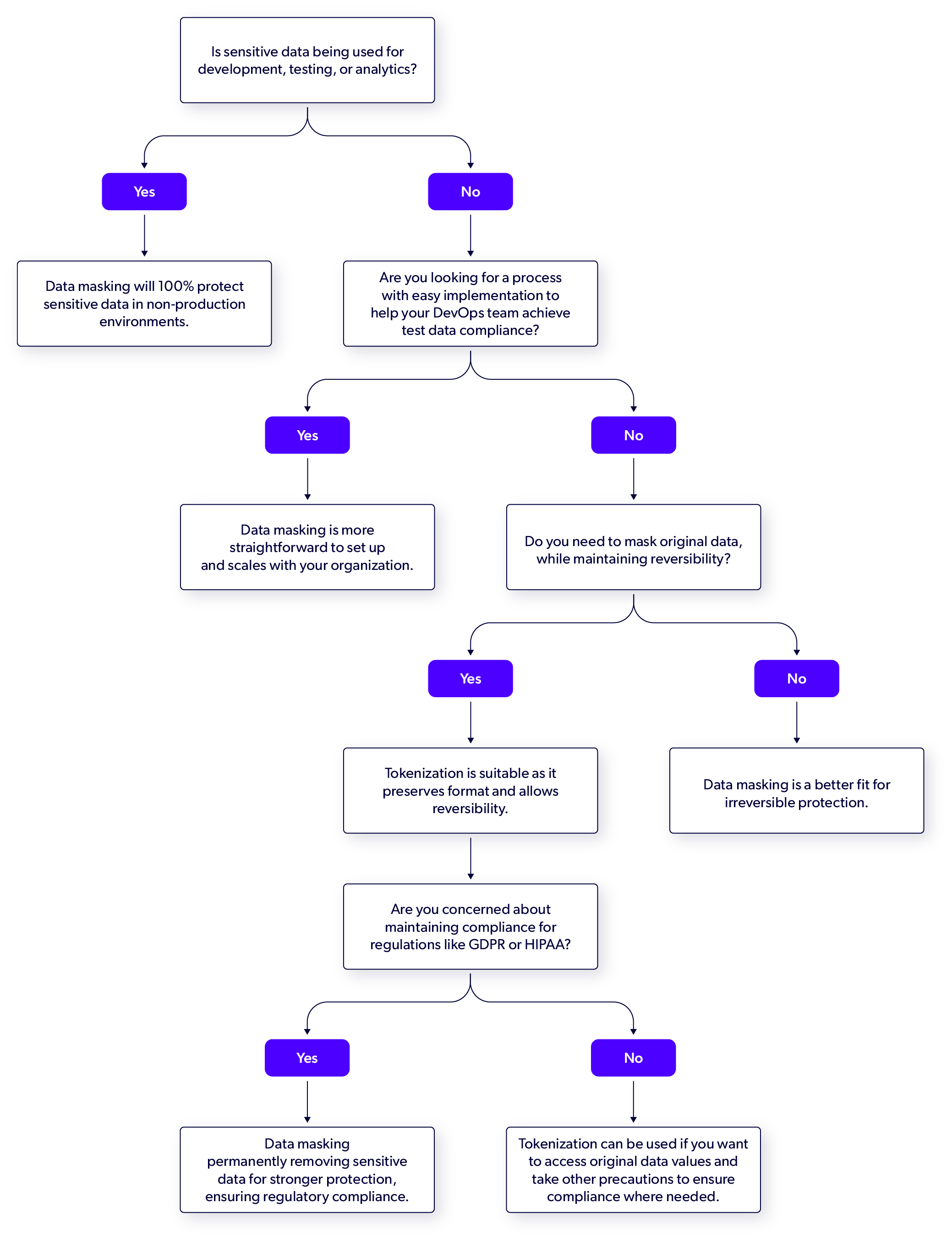
Many teams struggle to add masking or tokenization into their development processes. Security teams often work apart from development teams. This siloed work style can cause misalignments in the CI/CD pipeline. When data masking or tokenization isn't automatic, it leads to delays and manual fixes.
Developers sometimes use protected data for testing without verifying changes. This practice can lead to mistakes and incorrect assumptions about the data's functionality.
In one real-world example, a financial technology company I worked with tried adding masking to their development pipeline using scripts. But issues with settings and missing central rules caused test systems to expose private information and introduced data quality issues. The company had to conduct a complete audit to find the problems and rebuild their pipeline with better security rules.
Back to topProven Masking Results Across Industries
Organizations worldwide trust Delphix for comprehensive data masking and compliance. Here's how leading enterprises protect sensitive data while accelerating innovation:
Financial Services: Boeing Employee Credit Union
Boeing Employee Credit Union (BECU) needed a way to automatically find sensitive data and mask it the same way every time. Using Delphix, they masked 680 million rows in just 15 hours. This allowed over 200 developers to get self-service access to data.
“Not only does Delphix reduce our risk footprint by masking sensitive data, but we can also give developers realistic, production-like environments." — Kyle Welsh, CISO, BECU
Telecommunications: Proximus
Proximus struggled with its data masking, which was inconsistent across teams and had to be repeated over and over again.
Thanks to automated data masking with Delphix, the telecommunications enterprise was able to solve this issue and reduce the time it takes to refresh 60 applications from two weeks down to one weekend.
Insurance: Delta Dental
Delta Dental used to spend 8 weeks just extracting data. Protecting sensitive data for compliance was difficult. With Delphix, they can mask data and easily deliver it to a team of 200 developers in minutes.
Read the Delta Dental Case Study
Get Demo
Automate Data Masking & Compliance with Perforce Delphix
Perforce Delphix offers advanced data masking capabilities that help organizations navigate the complexities of data protection. A recent IDC study — IDC: the Business Value of Delphix, sponsored by Perforce Delphix — makes it clear: If you want to protect 77.2% more data and data environments, you need Perforce Delphix.
Delphix automatically discovers sensitive data, then irreversibly masks it with realistic yet fictitious values. It gives teams high-quality, compliant data for development, testing, AI, and analytics.
Related Blog >> What is Delphix?
Utilize Sensitive Data Discovery
Delphix automatically finds sensitive data across a broad array of databases, data warehouses, and data pipelines.
Want to see how sensitive data discovery works? Watch this quick demo from my colleague Felipe Casali and see for yourself how easy it is to discover sensitive data with Delphix.
After sensitive data is discovered, Delphix replaces that data with realistic, production-like values. This is done using a full library of pre-built and customizable algorithms. This method keeps the data useful and keeps relationships between data intact.
Delphix works across all your data sources — from small SQL databases and on-premises systems, to massive cloud platforms like Snowflake, Databricks, and Oracle.
With Delphix, compliant data is delivered quickly and automatically. Your development, testing, and analytics teams get the data they need, when and where they need it.
See For Yourself How Delphix Data Masking Works
With Delphix, you don’t have to choose between speed, quality, and security.
Get a no-pressure demo from our product experts to see how Delphix lets you ensure compliance, eliminate data risks, remove bottlenecks, and deliver higher-quality data for better AI and analytics outcomes.
*IDC Business Value White Paper, sponsored by Delphix, by Perforce, The Business Value of Delphix, #US52560824, December 2024