Branching and merging are staples of development. Here's how branching works in Subversion and how to use svn merge.
Back to topSubversion Branching Strategies
Subversion branches (SVN branches) allow your team to work on multiple versions of your code simultaneously. Developers can test out new features without impacting the rest of development with errors and bugs.
SVN’s “branch” directory runs parallel to the “trunk” directory. A SVN branch copies the trunk and allows you to make changes. When the new feature is stable, the branch is merged back.
Here's a basic step-by-step overview of SVN branching and merging.
- Create a branch using the svn copy command.
- Use svn checkout to check out a new working copy.
- Use a sync merge to keep your branch up-to-date as you work.
- Use svn merge to send your changes back to the trunk.
Back to topBranch Smarter With a Better Tool
Many teams have switched from SVN to Helix Core. That's because Helix Core guides developers through branching and merging. Try Helix Core for free for up to 5 users.
Drawbacks to SVN Branching and SVN Merge
The most common complaints about SVN is its tedious branching and complicated merging model. SVN branches are created as directories inside a repository. This directory structure is the core pain point with SVN branching. It costs what every developer needs more of: time.
Relationships Between Subversion Branches
Relationships between branches and the branch’s relationship to the trunk is not stored easily in SVN. Development must come up with a naming scheme or create external documentation.
SVN Merge in Parallel Development
As you’re working on your branch, you occasionally merge from the trunk to your branch to keep your directory up-to-date. Every time this happens, changes are copied and duplicated into your branch directory. This may or may not reflect changes other developers are making.
When the branch is ready, you commit back to the trunk with SVN merge. Of course, you’re not the only one merging changes. Your version of the trunk might not reflect developers’ branches. This means conflicts, missing files, and jumbled changes riddle your branch.
Let’s look closer at this example.
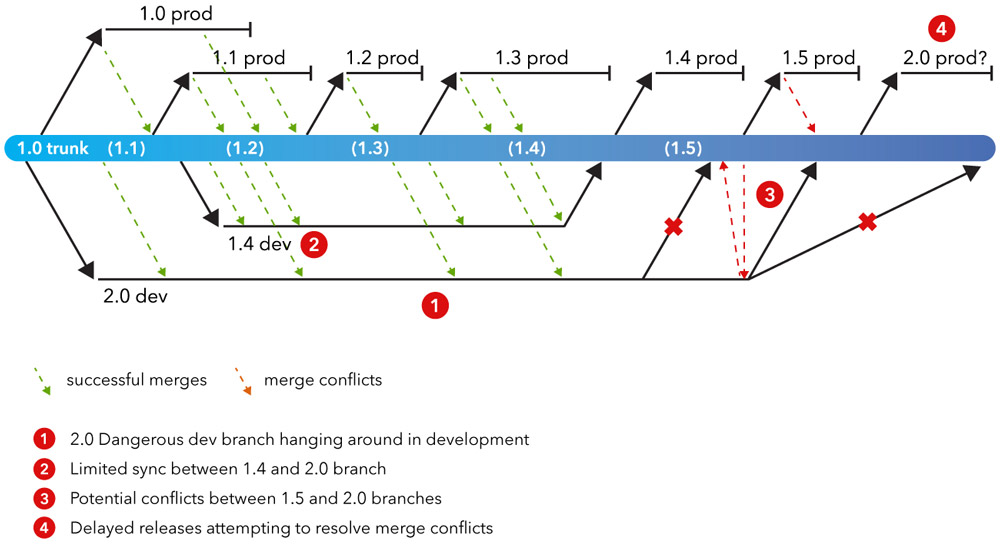
The 1.0 trunk has two developers working on separate releases. As the 1.4 and 2.0 dev branches are being worked on, they will merge from the trunk to the dev branch to gather updates.
Parallel SVN development creates limited visibility into other branches. When the 1.4 dev branch merges with the trunk, it is pushed out to development. This may happen with minimal conflict, but the same cannot be said for the 2.0 dev branch.
SVN Tree Conflicts
Long-lived branches have greater risk of issues. SVN does not tell you where your branch belongs on the trunk. You have to comb through code to figure out where it belongs and what changes are missing.
SVN tree conflicts usually occur when changes are made to the directory structure. This can happen when renaming or deleting files. Since these changes are quite common, you’re going to be searching for a while.
Since you can’t commit changes when there is a tree conflict, you have to manually resolve each error. Even with “merge tracking,” you might not be able to figure out what changes are missing from your branch. This can have major delays to deployment. Plus, as teams get bigger, the trunk can become less stable and harder to maintain.
Back to topHow to Stop SVN Merge Conflicts and Branching Problems
It’s clear that SVN branching and merging is a problem. Helix Core offers a powerful and easy approach to branching: Perforce Streams.
Developers can use Task Streams to work on a small portion of the project without impacting production or other developers.
Watch this short video to see how Perforce Streams works.
Streams define the purpose of each branch: mainline, development, task, or release.
They follow the mainline model that all changes flow toward the mainline, similar to an SVN trunk. It lets developers focus on their code — not the branch and merge.
Stream Graph creates a graphical representation of branch hierarchy. This means that your team always knows what everyone is working on. And exclusive checkouts and granular permissions for Streams creates even more visibility.
This streaming strategy solves a lot of the issues with SVN branching.
In Helix Core, there is no fixed naming scheme. Helix Core uses a separate database table to track every merge. And there are many ways to trace changes across branches: revision history, time lapse views, and revision graphs.
See for yourself how easy it is to branch with Perforce Streams. Try it yourself.
More on SVN:
- Is Subversion Free?
- TortoiseSVN
- How to Use SVN (and When to Migrate)