Guide
Preserving Referential Integrity Across Your Enterprise Data Estate

Security & Compliance,
Data Management
In my time working with large-scale enterprise data estates, I consistently see one hidden issue derailing release cycles: the collapse of referential integrity.
When data moves across multiple databases and pipelines, traditional data masking tools simply cannot maintain consistency at scale. I have watched engineering teams lose days chasing down application defects that turn out to be broken data relationships.
When masking logic operates in silos, tests become unreliable, false positive bugs multiply, and operational inefficiencies bring innovation to a halt.
In this guide, I will walk you through why standard point solutions struggle at the enterprise level, how compromised integrity disrupts your critical testing workflows, and how Perforce Delphix ensures referential integrity across complex enterprise environments.
Back to topWhat Do We Mean When We Talk About Referential Integrity?
At a base level, referential integrity (sometimes called relational integrity) refers to ensuring consistency in data transformations. If a name is transformed from Allison to Rebecca, it must become Rebecca in all places, or testing will break.
A good example is billing validation: A customer account may be associated with multiple products, charges, and invoices across several tables in a database. If referential integrity is not preserved, those relationships no longer align. The application may return incorrect products or calculate inaccurate charges, which leads to invalid billing outcomes.
In this case, testing is no longer validating application logic — it is validating broken data relationships.
What is Referential Integrity in the Context of an Enterprise Data Estate?
In the context of an enterprise data estate, referential integrity requires guaranteeing that all relationships between data elements across systems are logically consistent, valid, and complete.
At enterprise scale, it is much more complicated to achieve. According to the 2026 Perforce Delphix Test Data Management Report for AI-Ready Enterprises, 39% of enterprises identify data quality or validity issues as a top test data challenge.
Data is constantly copied, transformed, and distributed across many applications, clouds, and pipelines — each with its own schemas, refresh cycles, and integration patterns. As a result, even small mismatches in masking logic can break relationships. This causes tests to fail downstream.
Example: What Broken Referential Integrity Looks Like for a Major Retailer
Imagine an application that stores customers in one table and orders in another. In production, every order reliably points to a real customer.
In a test environment where referential integrity is broken, orders still exist, but the associated customer records are missing or inconsistent.
Tests may pass at the unit level, but integration tests fail when the application tries to assemble a complete customer view that no longer exists.

I’ve seen this pattern play out with large companies. It always leads to the same outcome: teams lose days chasing defects that aren’t real defects at all — they’re just broken data relationships.
Once those links fall apart, the entire testing and release process starts to slow down.
Back to topWhy Many Solutions Fail at Referential Integrity
While many tools can maintain referential integrity in a single database, they break down when data is moved throughout multiple databases.
I’ve seen this happen often. Solutions look fine in isolation but collapse under enterprise complexity. Most enterprise applications rely on multiple databases, often 3 to 5. This problem is further compounded by the fact different engineering teams typically own different services and data stores.
As a result, maintaining referential integrity is no longer a single-database problem. Relationships often span systems, schemas, and teams, which is where many solutions begin to break down.
Why Traditional Masking Tools Struggle
Masking Happens System by System
Most tools mask data independently in each table or database. Even tiny differences in logic or timing break cross‑system relationships. Teams end up chasing “application bugs” that are actually caused by inconsistent IDs.
Masking Algorithms Aren’t Truly Deterministic
Enterprise integrity requires deterministic masking, meaning the same input always produces the same masked output across every system, environment, and data pipeline. Many tools claim determinism but only apply it within a single database or masking job. Others rely on randomization or partial lookups, causing identical values to be masked differently across systems.
Over time, these inconsistencies break relationships and erode trust in non‑production data.
In contrast, Delphix uses fully deterministic — and still irreversible — algorithms to ensure consistency everywhere it matters.
Why Micro‑DB and Fabric‑Style Architectures Miss the Mark
These approaches manage data inside isolated containers or fabrics, but they don’t maintain global consistency. They optimize for local correctness, not enterprise‑wide integrity.
I’ve worked with teams who adopted these tools expecting simpler testing, only to end up with more fragmentation and inconsistent versions of “truth.”
Point Solutions Don’t See Full Lineage
Point tools operate on whatever data they can see. They don’t understand dependencies across pipelines or environments, so upstream changes don’t propagate correctly. That’s how organizations end up with mismatched customer records in CRM, billing, and analytics.
The Outcome: Misleading Tests and Broken Data
According to the 2026 Perforce Delphix Test Data Management Report for AI-Ready Enterprises, 43% of organizations say consistent, high-quality test data to reduce defects is a top priority for test data automation.
When referential integrity fails, symptoms appear everywhere: flaky integration tests, incomplete scenarios, inaccurate performance tests, and confused compliance and analytics teams. I’ve seen entire sprints lost to debugging issues that came down to nothing more than inconsistent masked data.
This is why scripts, point tools, and single‑system masking products can’t solve referential integrity at enterprise scale. It requires a platform built to enforce consistency across every system, every time.
(If you want to explore where point solutions and Micro-DB tools fall short compared to comprehensive enterprise platforms like Delphix, here’s an explainer: Delphix vs. Other Data Management Alternatives)
How Exactly Does Testing Break Down When Referential Integrity Collapses?
To better understand how exactly testing breaks when referential integrity is not maintained across systems, let’s take a look at how various types of testing are impacted:
I’ve seen unit tests give teams confidence early on because they isolate logic from real data relationships. At this level, broken referential integrity is easy to miss.
| What unit testing is trying to validate | Correctness of individual functions, classes, or services. |
| How it uses data | Isolated records, mocks, in‑memory datasets. |
| What happens when referential integrity is preserved? | Tests are stable and predictable. Logic behaves as expected because inputs match assumptions. |
| What happens when referential integrity is broken? | Tests still pass. Data relationships are rarely exercised at all. |
| Why teams get misled | Unit tests give a false sense of confidence. Passing results suggest the system is healthy even though no real data relationships were tested. |
| Example | A healthcare billing service validates charges correctly, but unit tests never catch missing patient links used later in claims processing. |
Functional tests surface issues that unit tests miss, but only when the data still resembles real application behavior. When relationships drift, results become unreliable.
| What functional testing is trying to validate | Feature‑level behavior within an application. |
| How it uses data | Small but realistic datasets, often within one system. |
| What happens when referential integrity is preserved? | Features behave consistently. User flows reflect production. |
| What happens when referential integrity is broken? | Tests become flaky or incomplete. |
| Why teams get misled | Failures look like edge cases or bad test coverage, not a data problem. |
| Example | A retail checkout flow works in tests, but fails when orders can’t resolve customers after masked IDs no longer align. |
I’ve found that integration testing is where referential integrity issues surface most clearly. This is often the first time that systems are forced to agree on shared data.
| What integration testing is trying to validate | Interactions across components, services, or systems. |
| How it uses data | Joins across tables, schemas, APIs, or platforms. |
| What happens when referential integrity is preserved? | End‑to‑end workflows work. APIs return complete responses. Systems agree on shared identifiers. |
| What happens when referential integrity is broken? | Tests fail loudly. Joins return empty results. APIs return partial objects or errors. |
| Why teams get misled | The application is blamed even though it is behaving correctly. Debugging focuses on code paths rather than data consistency. |
| Example | A bank’s payment service fails integration tests when masked account IDs no longer match across transaction and ledger systems. |
Watch How Delphix Ensures Referential Integrity in Integration Testing
If you want to see how Delphix makes integration testing easy, check out this video. My colleague Carlos Cuellar walks through how Delphix's virtual databases and self-service tools help teams manage, test, and roll back data effortlessly while keeping everything in sync across systems.
I’ve seen end‑to‑end tests fail in ways that feel random, even when the application logic is sound. This is where broken data relationships cause the most confusion.
| What end-to-end scenario testing is trying to validate | Realistic business workflows across systems. |
| How it uses data | Large, production‑like datasets spanning multiple sources. |
| What happens when referential integrity is preserved? | Scenarios behave like production. Complex sequences can be validated with confidence. |
| What happens when referential integrity is broken? | Scenarios collapse. Steps fail mid‑flow because downstream systems cannot resolve related data. |
| Why teams get misled | Failures are hard to reproduce and explain. Teams assume environment instability rather than broken data relationships. |
| Example | A healthcare claims workflow fails mid‑process when masked patient, provider, and policy records no longer resolve across systems. |
Regression tests lose their value when baseline data quietly changes underneath them. Broken relationships make failures hard to trust.
| What regression testing is trying to validate | Ensuring existing behavior still works after changes. |
| How it uses data | Known datasets are reused across releases. |
| What happens when referential integrity is preserved? | Regressions are meaningful. Failures reflect real behavioral changes. |
| What happens when referential integrity is broken? | Baseline data drifts. Tests fail even when no functional change was introduced. |
| Why teams get misled | Teams lose trust in regression suites and start ignoring failures. |
| Example | A financial reporting app fails regressions after a refresh, even though no code changed. Masked account links drifted between releases. |
Performance tests can look healthy simply because the data isn’t realistic. When relationships are missing, load patterns don’t reflect production.
| What performance/load testing is trying to validate | System behavior under realistic volume and concurrency. |
| How it uses data | Large datasets with realistic distributions and relationships. |
| What happens when referential integrity is preserved? | Performance metrics reflect real workloads and access patterns. |
| What happens when referential integrity is broken? | Artificially low load or skewed access patterns because relationships are missing. |
| Why teams get misled | Systems appear faster or more scalable than they really are, masking real production risks. |
| Example | A retail platform appears fast under load tests, but real traffic fails when missing order‑to‑customer links spike database lookups. |
Gartner Peer Insights™ Customers' Choice for the 2025 Voice of the Customer for Test Data Management
Perforce Delphix was recently cited as a Gartner Peer Insights™ Customers' Choice in the 2025 Voice of the Customer for Test Data Management*.
*Gartner, Gartner Peer Insights ‘Voice of the Customer’:
Test Data Management, Peer Contributors, August 2025

 Back to top
Back to top
Why Referential Integrity Is Foundational to Defensible Enterprise Compliance
Referential Integrity Makes Compliance Verifiable
For enterprise data compliance leaders, referential integrity is not just a technical concern. It’s what makes data protection policies provable.
When relationships between records break across systems, controls may look correct on paper, but they become difficult or impossible to validate in practice.
This was a core requirement for Boeing Employees’ Credit Union (BECU), where consistent masking across databases and flat files had to preserve referential integrity in order to meet internal compliance standards and pass audits with confidence.
I’ve seen organizations with strong policies struggle simply because their data no longer told a consistent story.
Audit Evidence Becomes Fragmented Without It
Audits rely on providing evidence that masking, access controls, and retention policies are applied consistently. When data relationships are lost during masking or replication, this evidence is fragmented.
Teams can show controls exist, but they can’t reliably prove they were enforced uniformly across related datasets.
Traceability Breaks When Data Relationships Break
Most regulations assume traceability. Teams must show how sensitive data flows, how it is transformed, who can access it, and how long it is retained.
When referential integrity is lost, sensitive attributes can no longer be reliably tied back to the individuals or transactions they belong to.
At Sky Italia, maintaining referential integrity across masked non-production environments was essential to demonstrating compliance with GDPR — particularly when multiple business‑critical applications needed to be validated under tight regulatory deadlines.
Without intact relationships, basic compliance questions become hard to answer with confidence.
DSARs, Breach Analysis, and Incident Response Suffer
Broken relationships surface quickly in DSARs and privacy requests. If identifiers don’t align across CRM, billing, and analytics systems, teams can’t be sure they have found all relevant data.
The same issue slows breach analysis, where teams need fast, accurate insight into what data was affected and where it exists.
 Back to top
Back to top
Why Referential Integrity Is Critical for Reliable Analytics and AI
Broken Relationships Undermine Data Accuracy
Analytics and AI pipelines rely on consistent identifiers to join data across systems. When referential integrity breaks, pipelines may still run, but the results no longer reflect reality.
Dashboards show incomplete populations, metrics drift, and teams struggle to reconcile results because systems no longer agree on what defines a customer, account, or transaction.
Feature Engineering and Identity Resolution Fail Quietly
The impact is most visible in feature engineering and identity resolution. Features are often built by combining attributes from multiple sources.
When relationships are inconsistent, features silently drop out or become misaligned with their labels. Identity resolution breaks down, creating duplicate or fragmented entities that corrupt downstream analysis.
AI Models Learn the Wrong Patterns
AI and machine learning workflows amplify these issues. Models may still converge, but on flawed or incomplete data. Bias increases, performance degrades in subtle ways, and failures become harder to diagnose once models are deployed.
I’ve seen teams spend weeks tuning models, only to discover the root cause was broken data relationships.
Trust in Analytics and AI Erodes Over Time
Over time, trust erodes. Analysts validate data instead of generating insights. Data scientists debug pipelines instead of improving models. The organization continues producing analytics and predictions, but with growing uncertainty about their accuracy.
Preserving referential integrity is what ensures analytics and AI systems learn from data that still represents a coherent, real‑world story.
Back to topHow Exactly Does Perforce Delphix Ensure the Referential Integrity of Data Across Enterprise Systems?
As a unified data delivery, governance, and compliance platform, Delphix ensures referential integrity across enterprise data estates. Delphix delivers automatic sensitive data discovery, irreversible static data masking, and a set of deterministic masking algorithms built for enterprise scale.
Here’s a high-level explainer on how data masking works in Delphix:
Now, let’s dive into exactly how these features work to ensure referential/relational integrity across databases:
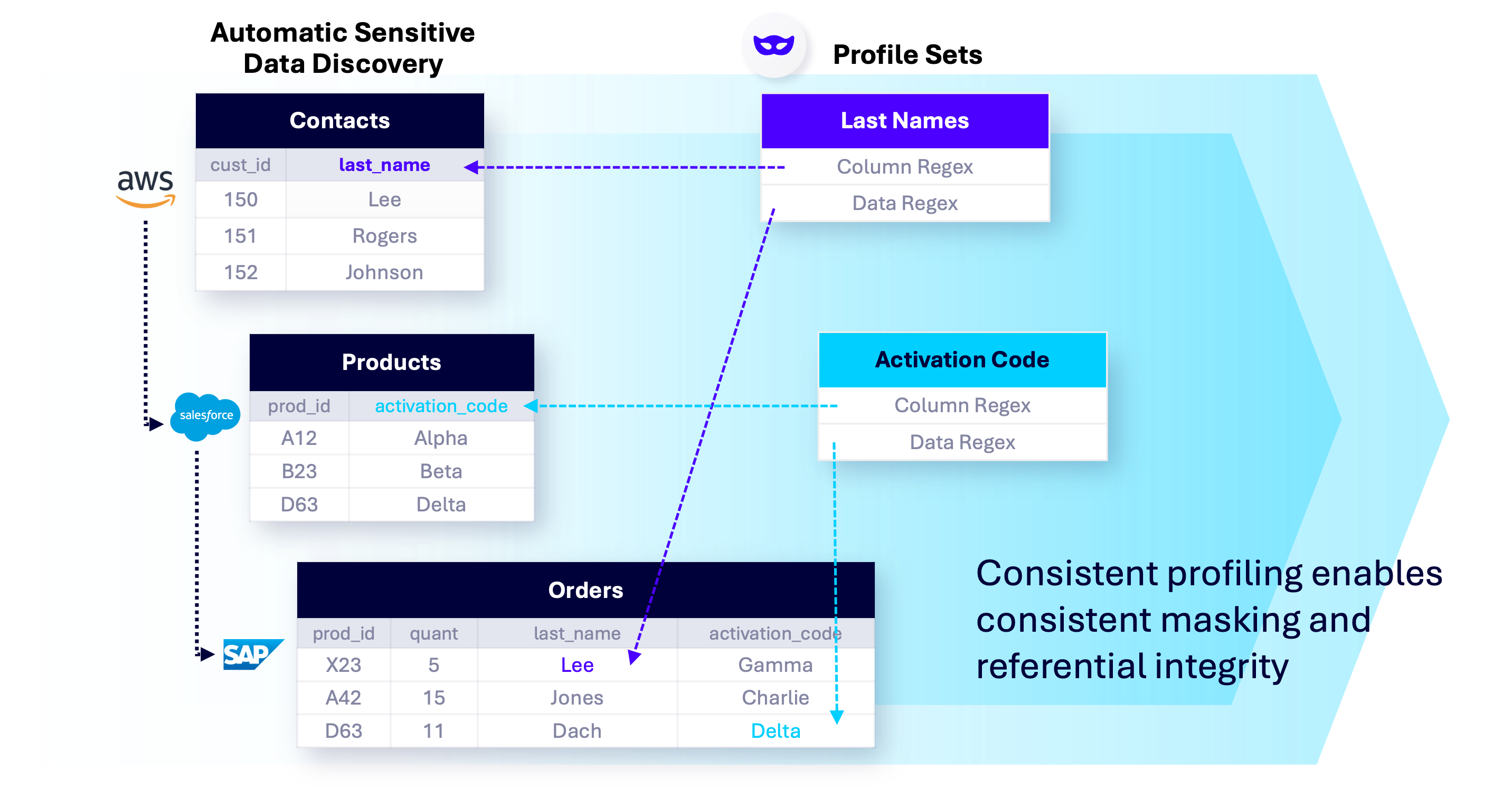
Automatically Discover Sensitive Data Across the Entire Data Estate
Delphix automatically scans enterprise data sources to discover and classify sensitive data before masking is applied.
This discovery operates across databases, warehouses, and platforms. By identifying sensitive data upfront, Delphix ensures masking policies are applied comprehensively rather than piecemeal.
Enforce Irreversible, Deterministic Masking for Consistency at Scale
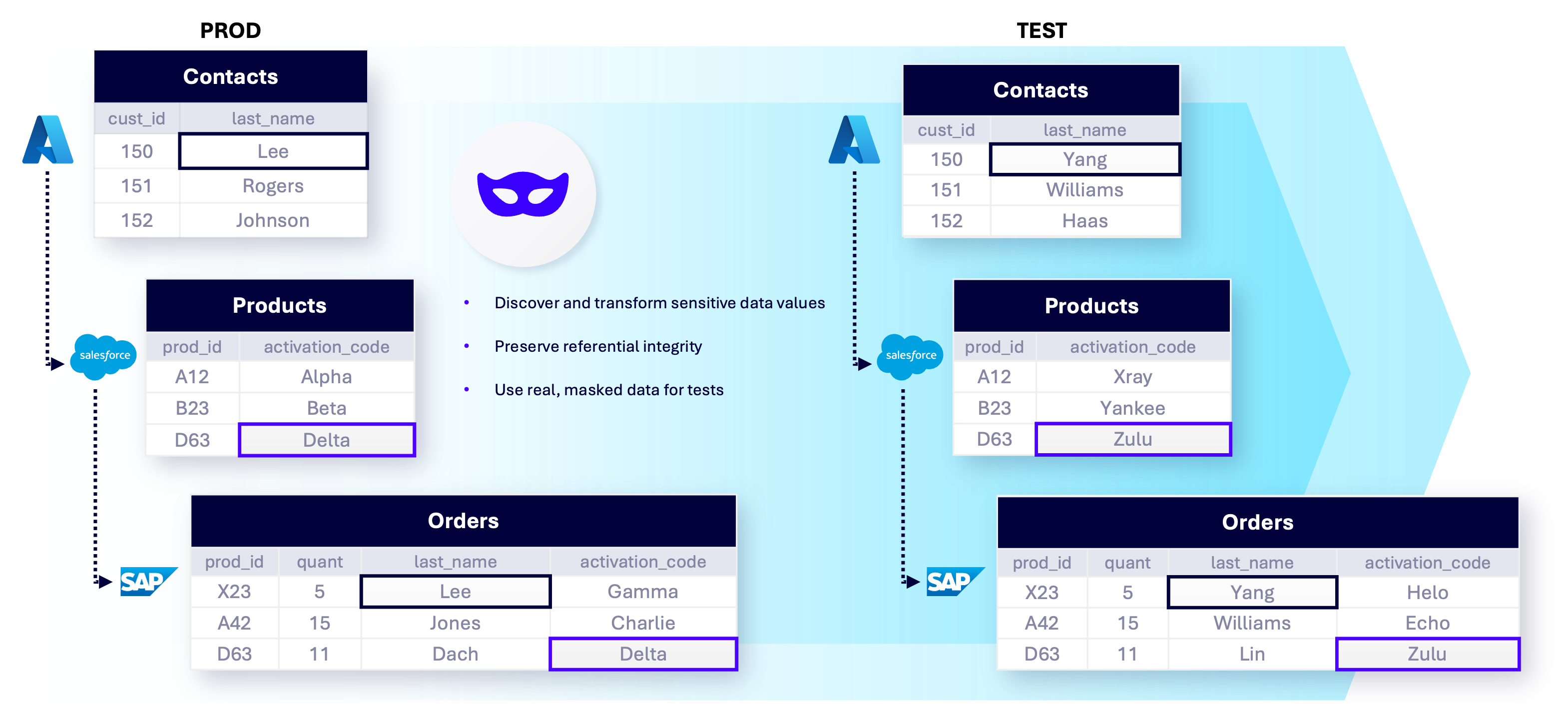
Data security requires irreversibility, while reliable testing and analytics require determinism.
Delphix uses irreversible static masking so original values cannot be reconstructed, even by users with administrative or database-level access.
At the same time, its deterministic algorithms ensure the same input always produces the same masked output across systems, environments, and pipelines. This balance is what allows enterprises to protect sensitive data without breaking relationships that downstream teams depend on.
Use Enterprise-Grade Masking Algorithms to Preserve Relationships
Delphix provides a broad set of masking algorithms designed to maintain referential integrity across complex data estates. These algorithms are applied consistently and at scale to preserve relationships within and across systems.
Delphix masking algorithm capabilities include:
Applies consistent value mapping so the same source value is always transformed the same way.
Uses controlled lookup tables to replace sensitive values consistently while preventing reverse engineering.
Applies deterministic masking to defined segments of a value, enabling consistent transformations where partial structure must be preserved.
Supports deterministic masking of binary or encoded data using lookups.
Replaces sensitive values with tokens that remain consistent across environments.
Preserves logical relationships between related dates (for example, start and end dates).
Masks payment card data while preserving validity rules and consistency needed for downstream testing.
Masks values based on combinations of multiple columns, ensuring consistency where relationships depend on compound keys.
Delphix allows enterprises to build custom algorithms when out-of-the-box options don’t meet specific relationship or compliance requirements.
If you want more detail on all of Delphix’s masking algorithms, as well as how exactly Delphix identifies and masks sensitive data at scale, check out this white paper, “Data Masking with the DevOps Data Platform.”
Perforce Delphix Accelerates Innovation with Trusted, Consistent Test Data
Perforce Delphix unifies data delivery, governance, and compliance in a single, secure platform. It automates the delivery of masked and synthetic data, giving your teams referentially-intact, production-like, compliant test data in minutes, not days. In fact, according to IDC Research, organizations developed applications 58% faster with Delphix.*
Related blog >> What Is Delphix?
Data Virtualization Transforms Data Delivery Speed, Storage
Delphix syncs with production data sources, then instantly provisions space-efficient virtual data copies for non-production use cases.
The result? Delphix accelerates provisioning times by 100x while reducing storage footprints by 10x.
Integrate Data Masking with Data Virtualization
The Delphix DevOps Data Platform combines masking with virtualization to deliver compliant data to downstream environments.
Delphix masking discovers sensitive values then irreversibly transforms those values into realistic yet fictitious equivalents, masking and protecting 77.2% more data and data environments.* Protect against breach and ensure compliance with data privacy laws such as GDPR, CCPA, HIPAA, or PCI DSS.
Get a Custom Demo: Fast, Compliant Data Delivery
Request a no-pressure demo of Delphix today to see why enterprise leaders trust it for reliable, compliant, fast test data.
See Referential Integrity at Enterprise Scale [Demo]
*IDC Business Value White Paper, sponsored by Delphix, by Perforce, The Business Value of Delphix, #US52560824, December 2024