Git and Perforce P4 are two powerful options for source code management, but choosing between them, or using both, depends on your specific use case and priorities. When evaluating these solutions, there's a lot to consider. So, we've broken down things to cover everything you need to know about Git vs. Perforce P4 in the table of contents below.
Or, want to test it firsthand? Try P4 free for up to 5 users and 20 workspaces.
P4 — complete with code review, Git support, endless integrations and client options — is free for teams of up to 5 users.
Follow along or jump to the section that interests you the most:
Git vs. Perforce P4 — What Are the Core Differences?
Every team has its own playbook, especially when it comes to version control.
When comparing Perforce P4 and Git, there are four main differences to understand:
Below is a breakdown of the key features of Git and Perforce to help you navigate these differences and choose the best fit for your workflow.
Feature |  | |
Version Control Type | Distributed | Centralized |
Use Cases | Software-development (including desktop or mobile applications), web development | Small to large teams across game development, animation, virtual production projects, 3D experiences, circuit design, and more |
Branching and Merging | Flexible, but can be complex for large projects | Strong support for branching and merging, especially with large files |
Performance with Large Files | Slower with binary or large files (blocks files over 100 MiB) | Optimized for handling large files and assets efficiently |
Storage | Stores all file versions on a central server but typically copies all versions locally, increasing local disk usage | Stores file versions on a central server and only sends a single version at a time, reducing local storage footprint |
Collaboration | Server-based, but each user as a complete local copy of the repository | Server-based, changes are synced to a central server |
Conflict Resolution | Can be more challenging, especially with large binary assets | Exclusive checkout helps avoid conflicts for unmergeable binary assets, and text-based merging is like Git's approach |
Security | Limited to user-level access, can be managed with tools like GitHub or GitLab | Granular permissions for file-level security |
Integration | Excellent support with CI/CD pipelines and third-party tools | Robust integrations with industry-specific tools like Unreal Engine and Maya |
Offline Work | Fully functional offline work with local repositories | P4 requires a connection to the central server for most operations.* *P4 One works offline, with optional syncing to a P4 server for wider collaboration. |
| Compliance | No built-in compliance standards | ISO 26262 certified to meet strict automotive industry safety standards |
Git’s open-source nature makes it a versatile tool that can be freely used, adapted, and built upon, which is why it’s the basis for many popular platforms like GitHub, GitLab, and Bitbucket. These platforms extend Git's core functionality, offering collaboration features (pull requests, issue tracking), user-friendly interfaces (through tools like GitHub Desktop, GitKraken, Sourcetree), CI/CD pipeline integration, and code review workflows.
This combination of core technology and ecosystem is a key aspect when comparing Git to Perforce. Git isn't just a version control system, but part of a broader, highly integrated toolset that many teams rely on daily. Git’s open standard allows it to work anywhere, including on a Perforce P4 server using the P4 Git Connector. This integration layer allows teams to leverage Perforce's enterprise-grade security and permissions features within the Git workflows they are already using.
Centralized vs. Distributed Model
The main difference between Perforce P4 and Git is in their underlying architecture and approach to version control. Git is a distributed version control system, and Perforce P4 (formerly Helix Core) is a centralized version control system—a key distinction for security and scalability.
Git
In a distributed version control system like Git, developers download source code –– along with a full version history –– to their machine. Once the full repository is downloaded, they can make changes locally—which makes local commits, diffs, and merges fast.
Problems with this model often arise when a team of developers, each working from their own copy of the repository, needs to coordinate and share changes. The question becomes: whose repository is the source of truth? Each developer having a copy of the repository on their machine also introduces security concerns, and containing or isolating those concerns can be difficult to manage.
This is why more and more teams today establish centralized workflows to manage Git-based technologies, both for coordination and security. Changes intended to become part of the project are submitted as a pull or merge request to a main branch. This is done on a dedicated Git server, instead of a single developer’s workstation.
Git permissions are also limited to the repo level. Teams with security requirements typically work around this limitation by breaking their projects into several repositories. This ensures developers only have access to the repositories they need and makes auditing easier. However, breaking up a project introduces painful cross-repository dependencies.
Centralized Git workflows like these still don’t address the more common collaboration challenge of avoiding file collisions and creating duplicate work. Individual users working on the same files often create merge conflicts, especially artist and designer roles working with binary files (3D models, images, multimedia assets, and more). When multiple team members modify the same files independently, Git's merge resolution capabilities can struggle, particularly with the non-text (or binary) assets common in game development, design, and other visual projects.
Perforce P4
Perforce P4 creates a single source of truth across all files—code, binaries, and large assets—through its centralized version control model. This centralized model means teams always work from the latest version, streamlining collaboration and eliminating file confusion. Developers around the world commit to one central server, creating a single source of truth that improves visibility and coordination across teams. Unlike Git, where work in progress is only stored locally, P4 makes in-progress changes visible across the team, improving communication and reducing file conflicts.
A centralized model makes asset collaboration and asset reuse much easier, and it assures auditability and traceability. Even though P4 is centralized, it securely supports remote sites through replica and proxy servers. This dramatically improves performance because most actions are done locally.
With granular access control at the file, folder, or IP address level, P4 helps teams enforce security policies and protect sensitive data. In contrast, Git's distributed model means every developer has a full copy of the repository on their machine, which raises security concerns for teams handling sensitive data.
Historically, Git’s distributed model made it a go-to for teams that needed flexibility and local control, especially for developers used to branching, rebasing, and pushing code independently. Perforce has long supported decentralized version control capabilities through its distributed version control system (DVCS), offering an alternative to Git.
With the release of P4 One, Perforce takes decentralized version control a step further by introducing Git-like workflows while maintaining P4’s speed, stability, and ability to handle large-scale projects. Unlike traditional branching, P4 One provides a lightweight alternative with first-class support for binary files, combining the flexibility of decentralized workflows with the benefits of a centralized model, such as exclusive file locking, if you connect to Perforce P4.
Performance
When it comes to performance, teams are often surprised when comparing Git vs. Perforce.
Git
Git’s distributed model allows developers to work independently on their local machines, making local commits, diffs, and merges incredibly fast. This offline capability is particularly useful for small teams or individual contributors who don’t need to frequently sync with others.
However, as teams grow and collaboration increases, Git’s performance can falter. Pushing and pulling changes to a shared repository often creates bottlenecks, especially for large projects. Git also has strict size limitations: files larger than 100 MB are blocked, and repositories exceeding 1 GB are discouraged, with 5 GB being the upper recommended limit. Managing merge conflicts and dependencies across multiple repositories can slow productivity, and Git can struggle with large files or binary assets, which limits efficiency in complex workflows.
Perforce P4
P4 was built for speed and scale. It can handle millions of transactions a day, billions of files, and petabytes of storage. Developers can quickly and easily see whether or not they have the latest version of a file on their workstation. Plus, it uses exclusive file locking, which prevents team members from stepping on each other's work, ensuring that no one is overwriting or conflicting with changes made by others.
P4 uses a federated architecture that lets remote teams experience local-speed performance for large clone/pull/build operations. Perforce P4’s software architecture ensures security while maintaining high performance, even for large teams and projects. Developers can work with confidence, knowing their files are protected without sacrificing speed. Granular permission controls protect sensitive data by granting access at the file, folder, or IP address level.
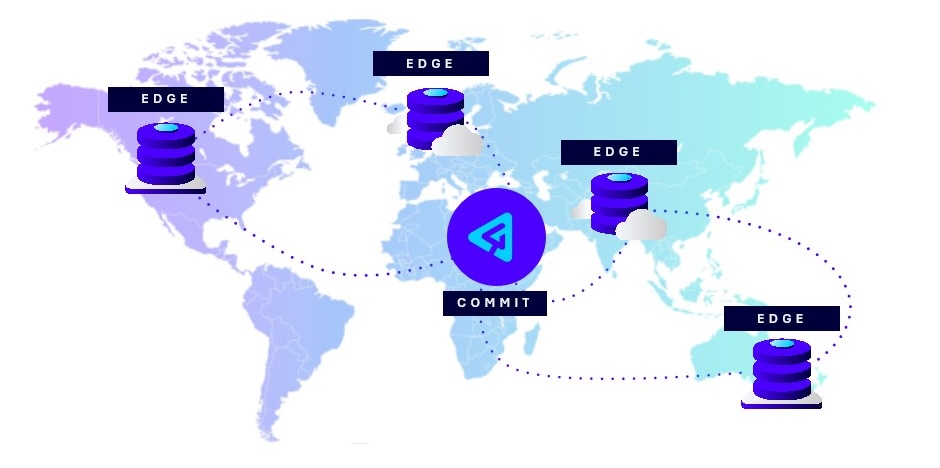
Features like Delta Transfer, which transfer only the changes made to files, and Virtual File Sync, which downloads metadata for infrequent files instead of the full content, significantly boost efficiency. These features help reduce storage costs, as well as data egress and ingress expenses, by minimizing the amount of data transferred across the network. For organizations managing large-scale data, these optimizations can make a substantial impact on overall infrastructure costs.
The availability of the P4 One version control client also provides a way for teams to work locally, while still maintaining a centralized and secure P4 workflow. With P4 One, a creator can version their project, code, and asset files on their local machine, at speeds up to 10x faster than Git. This enables offline work, experimentation, and project refinement without interruptions. P4 One lets users work independently and optionally submit changes to a P4 server. Single users can version control locally and transition to centralized P4 workflows when collaboration or scaling demands it.
Managing Large Files/Binaries
Large files and binary artifacts are part of development. They can be the result of builds and inputs into testing. But for some industries like semiconductor, automotive, game development, film, and television production, large files and binary artifacts are integral to your whole process. You need to be able to combine both the artist's and the developer's work into the final product.
Git
Today, Git attempts to address this with Git LFS, but it has significant limitations. While Git LFS stores pointers in your repository instead of actual binary files, it struggles with repositories exceeding 50GB and individual files over 5 GB. But most large teams store their large binary assets in an artifact repository tool, like Nexus or Artifactory. This means you no longer have a single source of truth. These additional tools also complicate your build pipeline.
Triple Boris evolved from an indie studio to a co-developer of AAA games, leveraging Perforce P4 and P4 Plan.
Perforce P4
In P4, text and binary files are treated equally, so all code, assets, and build artifacts are stored on one server. Having everything in a single source of truth makes workflows, security, and build pipelines simple. Now, your admins don’t need to manage additional licenses and integrations.
For teams handling both code and creative assets, P4 offers two clients:
- P4 Visual Client (P4V) equips administrators and developers with tools to manage streams and branches, configure permissions, visualize history, automate workflows, and handle complex merges, giving technical users complete control over their version control environment. For example, an admin on a game development team could manage multiple feature branches while maintaining a stable main branch for releases, all with a visual representation of how code flows between environments.
- For art and design teams, P4 One offers an intuitive way to track file progress, with a built-in image viewer that supports common file formats used for 3D modeling. For example, a 3D character artist using P4 One can visualize changes made to a single file directly within the interface (and without ever opening a digital content creation tool like Blender).
Branching
Both Git and Perforce offer lightweight branching. Although both track branching differently.
Git
In Git, when a branch is created, you can instantly start work on the local new branch. After you’ve made your additions and changes, and you’re ready to commit, you can either merge or rebase the history. But merging with your local copy of the main branch is not the same as pushing your changes to the remote repository.
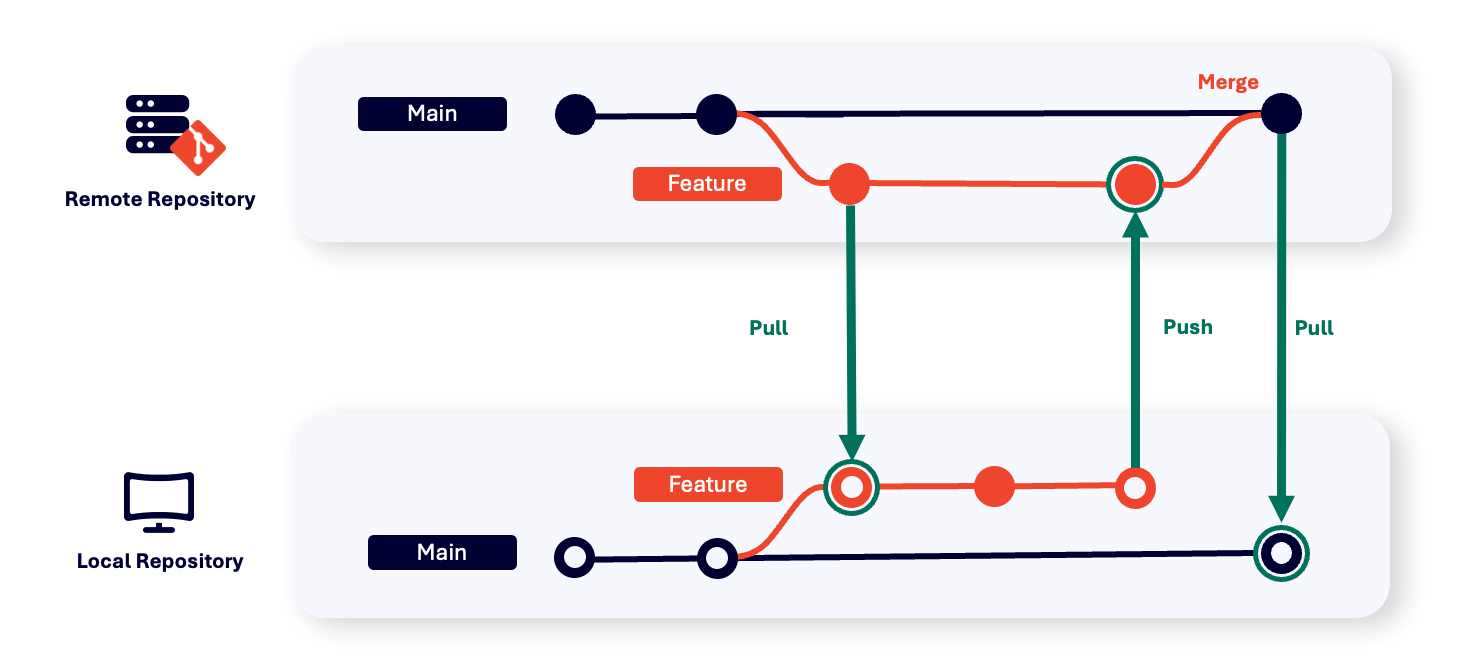
If multiple developers are working on the same files when you push your changes, merge conflicts can arise, making it difficult to work with multiple branches. This is why it’s always important to get the latest changes from the server before merging. But if you have hundreds of developers working on a project in Git, this can be time-consuming.
And if you have cross-repository dependencies, then you need to coordinate merge conflicts across repos. This can be tricky, and it gets harder as your team, or the number of repos, grows.
Perforce P4
In P4, branches are done at the file hierarchy level. Your team members can pick and choose specific files to checkout and submit back into the repository. Exclusive checkouts give developers visibility into what other people are working on and avoid the need to branch as often, especially for teams working with binary files. And with granular permissions down to the file level, admins can keep their most important files protected. Because P4 uses a centralized server, developers gain visibility into what other people are working on and enable admins to specify files that cannot be merged (such as most art assets) to be exclusively checked out by one user at a time. This avoids merge conflicts on binary files, saving users from having to redo large amounts of work.
To dive deeper into branching strategies, see the How to Automate Your Branching Strategy guide.
Perforce Streams, our way to branch and merge, simplifies workspace setup and helps guide teams. Developers can easily switch between streams (branches), and it’s easy to see how changes are propagated. For larger codebases, our Sparse Streams are a newer way to create branches much faster, even with huge projects, addressing a key concern for enterprise-scale development.
As with Git, when submitting changes to the main stream/branch, you can still get conflicts. These are generally easy to manage. The advantage of P4 is the visibility into work in progress, and the advanced notice for potential merge conflicts.
In addition, the scalability of P4 allows developers to submit a large changelist, affecting multiple components, in a single action. This significantly reduces issues with code dependencies that would require cross-repository management in Git. P4’s scalability also makes it easy to track and manage these complex changes throughout the development lifecycle.
Get started with Perforce Streams and speed up your branching process in our Streams Adoption Guide.
Perforce Sparse Streams
Git is often praised for its fast, lightweight branching. But as repositories grow, their advantages fade. Developers must clone entire repos, leading to bloated storage, slow operations, and frustrating delays, especially in large-scale or enterprise environments.
For teams working with thousands—or even millions—of files, version control shouldn’t dictate how you work. That’s where Perforce Sparse Streams come in, built for modern dev workflows. Whether you’re iterating on a feature, squashing a bug, or working in a large monorepo, Sparse Streams helps you:
- Quickly spin up a short-lived task branch
- Reduce the volume of metadata stored
- Keep your workspace clean and focused — only pulling in the files you need
- Improve performance across massive projects with complex dependency chains
- Save storage space — Sparse Streams don't copy the entire branch; they simply reference the necessary files, reducing storage requirements and improving performance for large codebases
- Optimize metadata usage — only the relevant metadata is stored, helping to keep the server lean and efficient even as projects scale to enterprise size
Unlike Git, where you often need scripts and external tools to manage branch relationships, Perforce Sparse Streams visualizes branch hierarchies, saving your team time and reducing merge errors.
When to Use Sparse Streams
Sparse Streams are ideal for when you want to make a big change to one part of a project, in isolation, before merging it back into the full project. This is great for new features or bug fixes because new metadata is only created for files that are changed in the new Sparse Stream. Unlike Git, where branching is fast but can become difficult as your project scales, Sparse Streams lets you maintain the speed of Git-like workflows with the power of Perforce's centralized version control system. You can demo Perforce Sparse Streams here.
Back to topWhich Workflow Is Right for You?
Choosing the right workflow comes down to your team’s needs and the complexity of your projects. Here's a closer look at what makes each stand out:
- Git is ideal for smaller teams working on singular software development projects, like desktop or mobile applications, or web development, where simplicity, speed, and developer familiarity are key.
- Perforce P4 excels in asset-heavy pipelines where large binary files, stricter security, and wider collaboration needs are part of the daily workflow. It's ideal for anyone using a game engine to create video games, VFX, animation, digital twins of automotive or manufacturing systems, or VR/AR experiences.
Both Git and Perforce P4 offer powerful solutions for version control, while the hybrid approach using Perforce's P4 Git Connector bridges the best of both worlds.
When to Use Git?
There’s a reason why so many teams choose and use Git.
It solves the most basic version control problems for small-to-medium text-based projects. Developers can collaborate on the same code project while maintaining their version history, so they can simultaneously work on the same code project.
It’s fast for local operations. Git is often the first version control system developers use in universities. Most developers use and know Git commands like clone, commit, and push. Plus, it’s free, and its open-source nature eliminates licensing costs, making it accessible to individuals and small teams. Because of public services like GitHub and Bitbucket, Git is also a great solution when working on open-source projects where anybody can download or contribute new code.
Teams That Use Git as Their Version Control
Small teams who work on a singular software development project at a time often prefer Git. It works well for projects like web or app development, where all files are primarily code-based, and the team doesn’t need to manage large files or complex workflows.
Example: A small VFX boutique working on a short film might use Git to version their Python pipeline tools and the codebase for their marketing website. In some cases, compositing scripts may also be backed up in Git, not for day-to-day collaboration, but as a lightweight disaster recovery solution. Git’s distributed model gives technical team members the flexibility to work remotely or offline, pushing changes to a remote repository when ready.
Git for Large Enterprises
Over the past two decades, many commercial companies have built successful business models around open-source software, including GitHub, GitLab, and Atlassian. They’ve added user interfaces, code review workflows, management capabilities for multiple repositories, and pipeline integrations to Git.
Example: Microsoft uses Git for managing source code across large, distributed teams. With Azure DevOps and GitHub (which Microsoft owns), they maintain extensive open-source projects like Visual Studio Code and smaller department-level repositories. Git’s decentralized nature enables thousands of developers to collaborate, contribute to codebases, and roll out updates rapidly.
When to Use Perforce P4?
Perforce P4 excels with larger codebases and projects involving binary files or a game engine workflow. Perforce P4 is the right version control system when you have:
- Large codebases.
- Non-code assets, like binaries or graphics.
- Code dependencies, particularly across components.
- Extensive code reuse, such as artifacts.
- Large, geographically diverse teams.
- A need for granular security controls.
A Note on AI: AI tools like ComfyUI and Tray.io are streamlining workflows, from generating assets to automating processes. While Perforce P4 doesn’t integrate directly with these tools, its robust version control capabilities make it an ideal foundation for managing AI-generated assets and workflows. Unlike other solutions, Perforce P4 doesn’t dictate how you should use AI tools or which ones to choose. Instead, it focuses on what matters most: versioning critical assets. This flexibility allows teams to integrate AI into their workflows without being locked into specific tools or processes.
Just P4: For Teams Needing Centralized Control and Scalability
If your team handles large-scale projects with complex workflows and needs security assurance to protect your assets, Perforce P4 is a great option.
Example: Halon Entertainment, a full-service studio, needed to manage enormous assets and streamline collaboration across teams. By switching from Git to Perforce, they ensured a smooth workflow that supported fast-paced iteration and secure file management.
"We used to rely on shared folders and Git for everything from scripts to assets. When we rebuilt our pipeline and transitioned to Python and Unreal Engine, we knew Perforce P4 had to be the foundation."
— Rogerio Gasi, Director of Engineering, Halon Entertainment
With Perforce P4, everything is stored in a single, centralized location. This means developers and creative professionals always have access to the latest files, and the system can handle millions of operations seamlessly. Teams like Halon that prioritize IP security, project visibility, and scalability for large assets find P4 invaluable.
Back to topWhen to Use Git + Perforce P4?
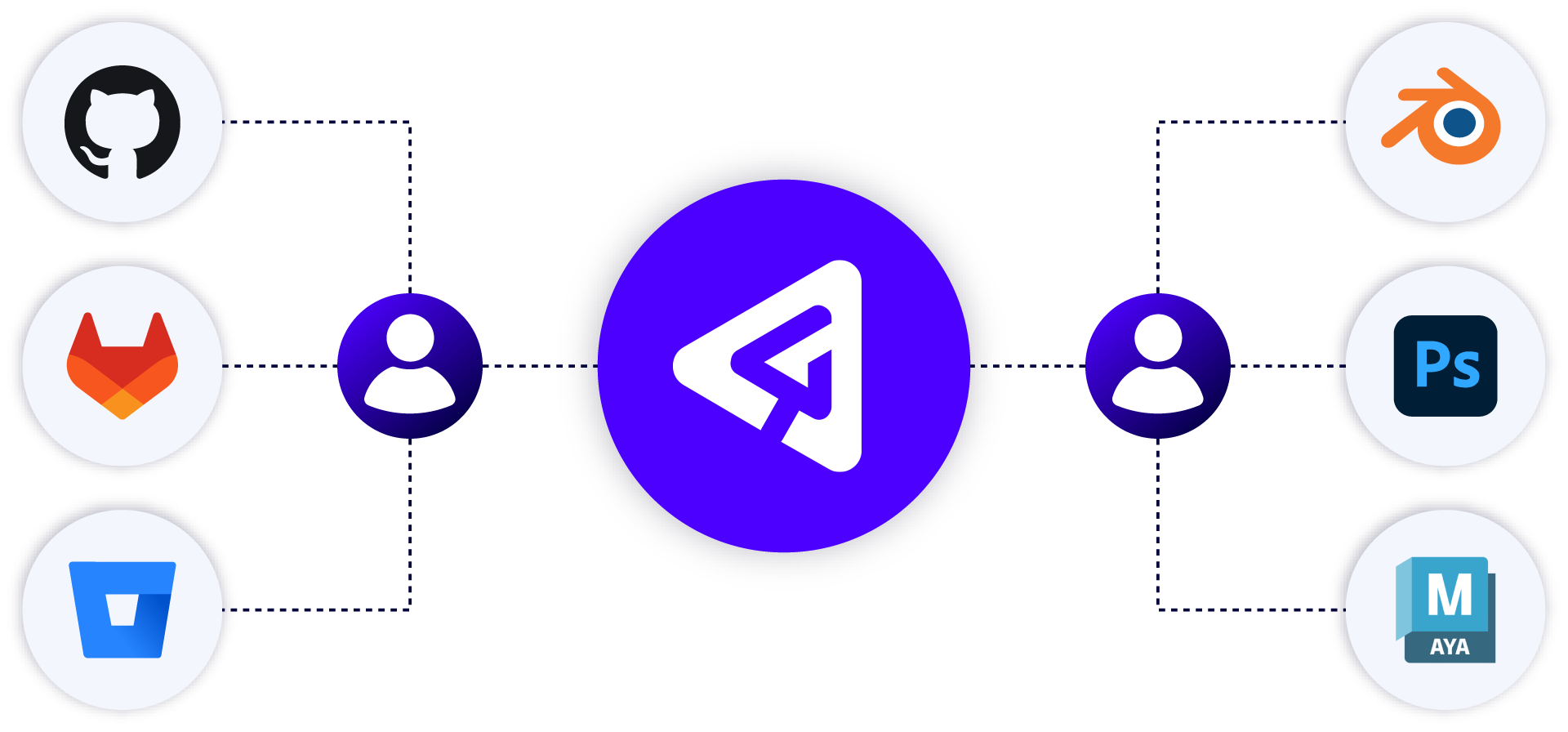
When comparing Perforce P4 and Git, many organizations realize they need the enterprise scalability of Perforce P4 while allowing developers to keep using their familiar Git workflows. With the P4 Git Connector, you can use both together seamlessly.
P4 Git Connector natively stores Git repos, with the speed and reliability of the Perforce P4 server. This solution is unique in the industry and supports your DevOps evolution. To get started, take a look at the P4 Git Connector QuickStart Guide.
Git’s Benefits for P4 Users
Your developers can still use Git commands like merge and rebase, create submodules, and more. This is because they have access to either solution, without any changes to their workflow or environment.
You can add P4 Git Connector even if you are in the middle of a project, and you can store your Git repos natively in P4, which also supports Git LFS artifacts.
For more information on P4 Git Connector, visit the FAQ page here.
Key Benefits:
- Developers keep using familiar Git commands and workflows.
- Organizations gain Perforce's enterprise-grade security and scalability.
- A single source of truth simplifies CI/CD processes.
- Faster Git operations (80% speed boost) with 18% less storage required.
P4 Git Connector ensures teams get feedback faster, giving developers, release managers, and CI/CD teams more hours back in their day.
Ready to get started? Visit the P4 Git Connector QuickStart Guide.
Git vs. Perforce P4 for Game Development
When it comes to game development, Git doesn't cut it. Although it’s great for code, it falls short of being able to manage the large number of files, extremely large files, and diverse asset types associated with game development. This is why game dev teams choose Perforce to manage it all, while still providing access to Git code.
Other industries have discovered the value of the game industry’s innovations. Many automotive companies have adopted similar workflows and integrated P4 to manage their vast and complex design files. They can deftly manage large projects while maintaining traceability for strict safety compliance.
Get Started with Perforce P4
See for yourself why P4 is a smart choice when it comes to choosing between Perforce P4 and Git.
P4 — complete with code review, Git support, endless integrations and client options — is free for teams of up to 5 users.